// model evaluation & validation · theory
In the modeling section under supervised learning, we tried to predict and classify our data using various techniques such as Linear Regression, Logistic Regression, KNN, ANN etc. However, we didn't explore any methods to find whether the model was predicting/classifying correctly or not. On top of that, all the models were created on the training dataset.

These two things will be explored in this section where, under Model Evaluation, we will explore the various techniques that can be used to find if the model is working properly, which is done by comparing the values predicted by the model with the actual values. Thus the model evaluation is done for the models that work under the supervised learning setup where the actual labels are available.
The idea of having training and testing dataset stems from the concept of generalization and the problem of underfitting and overfitting and the need of having a balance between bias and variance. All this has been mentioned occasionally in the modeling section, but in this section of model validation, we will get into the detail of the ways we can solve this problem of over and underfitting through the use of various resampling methods.
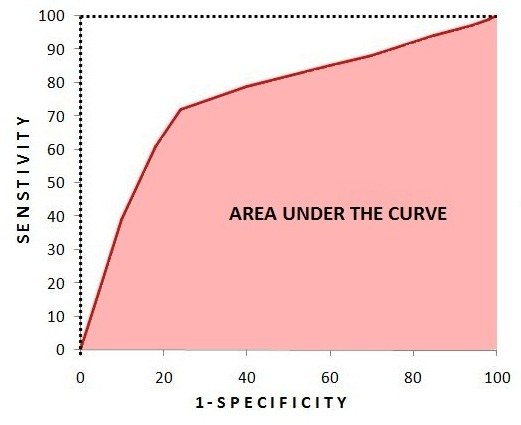
There are various methods of comparing the actual and predicted values/labels that help us in evaluating our model. In Regression Models, we evaluate the model based on the difference between the actual and predicted value. On the other hand, evaluating a classification model can become tricky as the predictions of the class label heavily rely on the cut-off value, making the evaluation a bit difficult.
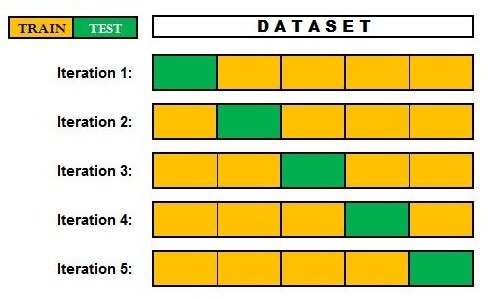
The Model Evaluation Methods tell us about how well our model is working but fail to address the problem of overfitting. Eventually, our aim is to predict/classify the data that our model has never seen or been trained on, and overfitting is the biggest cause of concern. Model Validation techniques are used to make sure that the results provided by the evaluation methods are not artificial and will hold true when the model is made to face unseen data.