// modeling · theory
Data Analysis can be of many types, from simple data exploration to creating data models that take help of various statistical and machine learning algorithms for performing various tasks such as Prediction, Classification etc.

In this section, the theoretical aspects of these algorithms are explored. Here the working of various algorithms along with their pros and cons are discussed. The data models can be created in various environments such as Supervised Learning, Unsupervised Learning, Reinforcement Learning etc.
In Supervised Learning, algorithms are supposed to predict either continuous values (Regression Problems) or categorical values (Classification Problems). Here we divide the variables of the dataset into two broad categories, the independent variables and the dependent (aka response) variable. In the Supervised Learning setup, we try to map a relationship between the independent and the dependent variable and make the algorithm learn a function which then predicts the values of the dependent variables based on the independent variables. Neural networks can also be used in Reinforcement Learning, where instead of learning from labelled targets the algorithm learns by trial and error from a reward signal. However, the Artificial Neural Networks discussed here are trained with backpropagation on a labelled dependent variable, which makes them a supervised method, and so they have been included under Supervised Learning only.
Unsupervised Learning Models are devoid of any dependent (response) variable and the algorithms are left to map a course on their own and come up with useful insights. Here evaluating a model becomes difficult. Unsupervised Learning is used for clustering, anomaly detection and feature reduction.
Another type of models that can be created is the Time Series Model. They are similar to the problems solved in the Supervised Learning setup as values are to be predicted here, however here the Time is considered as it becomes the most important factor in deciding the values. Here the values for the upcoming time period are forecasted.
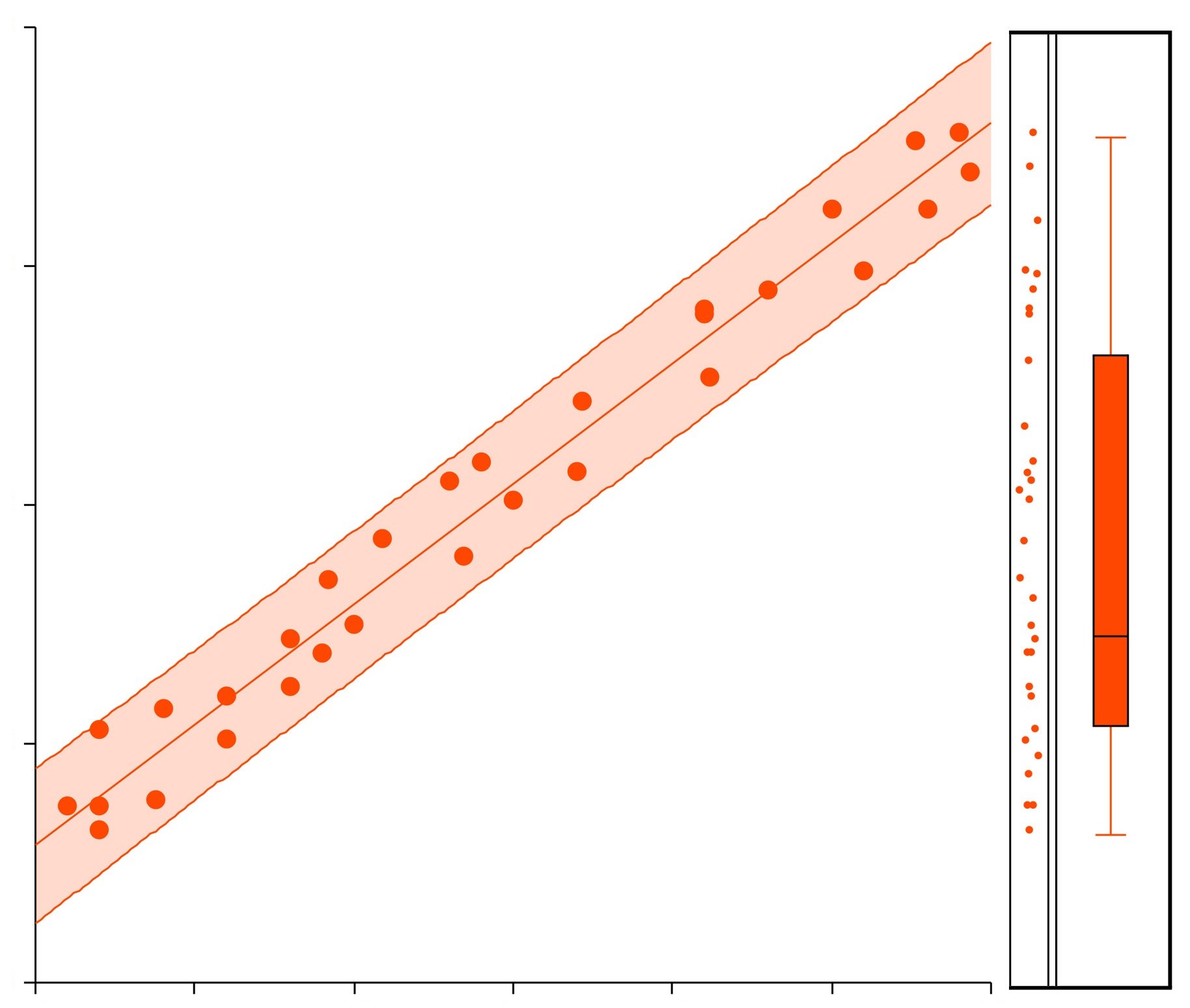
Most of the learning algorithms work in the Supervised Learning setup where the process of prediction is supervised as the algorithm is specifically instructed about what is to be predicted. The supervised learning setup involves a dependent well-labelled variable which helps the learning algorithm in coming up with predictions and also helps in evaluating them for better results.
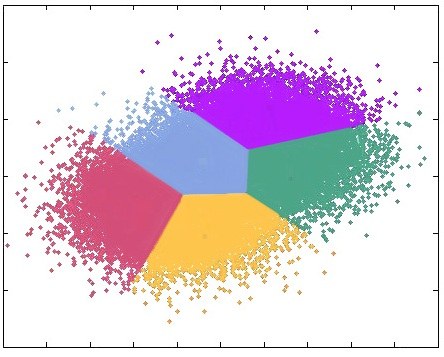
Certain models work in an unsupervised learning setup where there is no labelled dependent variable and the algorithm doesn't know / is not instructed to predict anything particular. Here the algorithm produces patterns and structures of the data which helps in performing tasks such as clustering, dimensionality reduction, anomaly detection etc.

Unlike Supervised Learning where a labelled dependent variable is given or Unsupervised Learning where the algorithms don't know what it is supposed to predict, Time Series models are created when we have to predict values over a period of time i.e. forecasting values. There are various methods for performing Time Series forecasting such as Smoothing, Time Series Decomposition, ARIMA etc.