// data exploration & preparation · miscellaneous methods
Various actions performed on the data can be categorized into Data Exploration and Preparation. Among such actions is the consolidation of datasets, uni-variate and bi-variate analysis, missing value and outlier treatment.

We can perform various uni-variate and bi-variate analysis that help us in exploring a dataset.
Consolidation of the dataset is another important activity where various datasets are consolidated through the means of appending, merging etc.
Outlier Treatment is another very important step where outliers are identified and treated. There are also highly sophisticated methods of identifying outliers which have been discussed under Anomaly Detection (Section 3, Modeling).
Missing values, as briefly mentioned in the introduction of the theory section, can be very harmful and various simple and sophisticated methods can be performed to treat such values. All such methods may be required to put into practice when preparing data for modeling and are explored in the following blogs.

The two main methods of consolidating datasets are appending and merging. In appending, the various datasets are combined vertically while in merging, datasets are consolidated horizontally. Here we also understand the various types of relationship that two datasets might share such as One-to-One, One-to-Many, Many-to-Many. Once the relationships are understood, the different ways of merging can be explored which include Inner Join, Left Join, Right Join, Full Join etc.

Various inferential and descriptive statistics are used to explore the data and get a better understanding of it. Under uni-variate analysis, each feature of the dataset is individually analyzed. Here different descriptive statistics are used to explore categorical and numerical features of a dataset. Bi-variate analysis, however, deals with two features where combinations of features such as numerical-numerical, categorical-categorical, numerical-categorical are analyzed and explored.
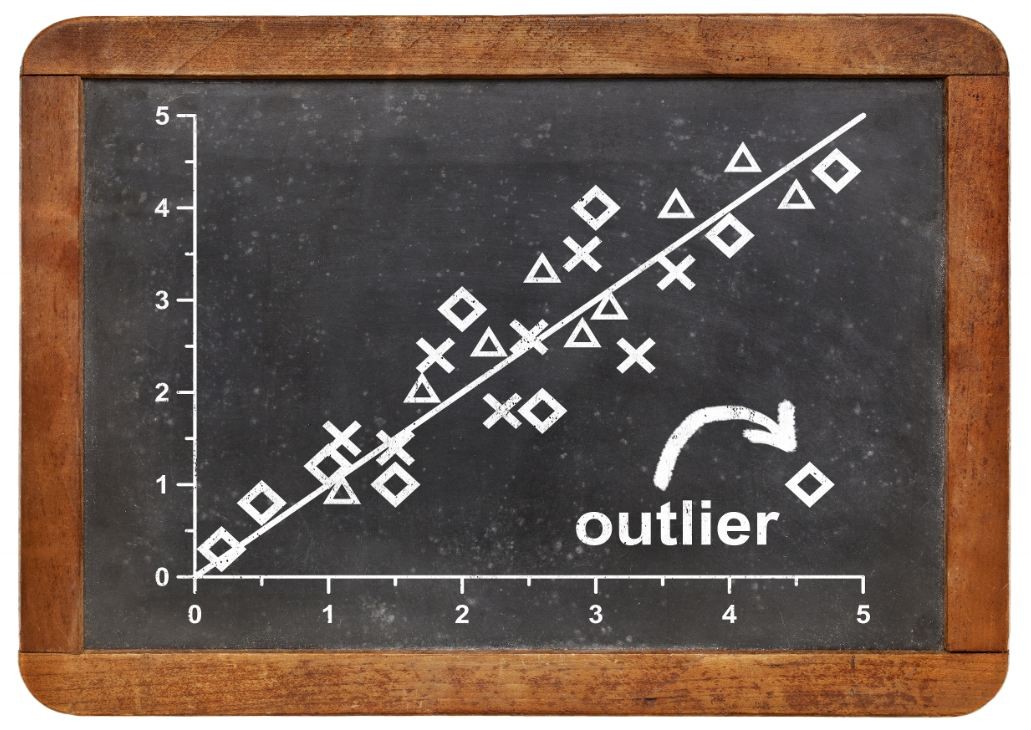
Outlier treatment is among the most important and tricky aspects of data pre-processing as it can greatly affect the outputs produced by the learning algorithms. Methods of outlier treatment include deleting observations having outliers, identifying and replacing outliers through the use of box-plots, quartile ranges, quantiles/percentiles, standard deviation, etc. Other sophisticated methods of identifying outliers include clustering along with the various methods of anomaly detection explored in the Modeling section.

Different types of missing values are explored here. Once identified, different treatment methods can be put to use to minimize the adverse effect that the missing values may cause to the model's performance. The most common methods include treatment of missing value by discarding observations or through mean/median/mode imputation. Other sophisticated methods include the use of prediction models such as Linear/Logistic Regression or the most common, KNN.