// unsupervised learning · dimensionality reduction
The problem of multicollinearity gives rise to the biggest problem of data modeling, Overfitting. The reason for multicollinearity is having correlated features. Often, the amount of data that one gets can be overwhelming with a lot of features, making the task of data exploration very tough. The high amount of data has its own disadvantages, such as it increases the computational time, decreases the storage and, most importantly, causes multicollinearity causing the models to overfit.

Dimensionality Reduction helps us in reducing the processing time, allowing us to perform more complex algorithms. Another benefit of having the data in low dimensions is that it frees storage space. These benefits, however, are all hardware related. The most important benefit of Feature Reduction is that it takes care of the problem of multicollinearity. Thus Dimensionality Reduction helps in making the process of data analysis faster and more accurate.
The two most common techniques that work in an Unsupervised Setup that can be used to reduce the dimensions of the data are Principal Component Analysis and Factor Analysis. Principal Component Analysis is where the data from a high dimensional space is reduced to lower dimensions. In simple words, we transform our features into a lower number of artificial features without losing much of the information. In Factor Analysis, the features are grouped based on their similarity which is determined by their shared variance, and then the user can pick relevant features from these groups, making the feature set unique and less vulnerable to multicollinearity.
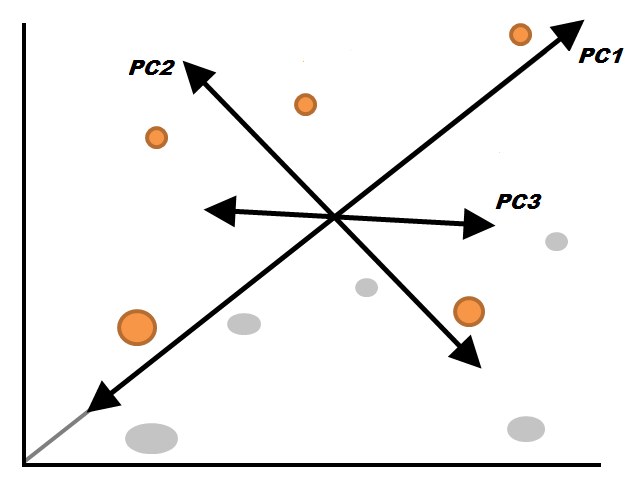
In this method, features are transformed into a set of 'artificial features'. These 'artificial features' are known as Principal Components, where the first component contains most of the information that can be contained in a single 'artificial feature' and we are left to select the number of components in order to reduce the features. Here the features are not explicitly dropped; rather the variation is extracted, saving the loss of data.
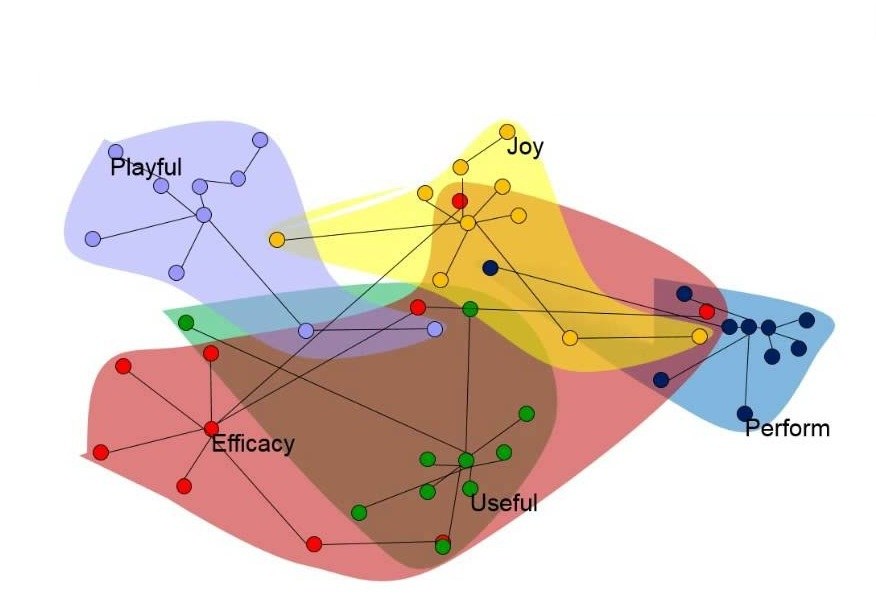
Correlation Coefficient plays an important role in Factor Analysis. A classification technique, Factor Analysis can be used as a dimensionality reduction method. Here groups are created by combining highly correlated features, where the groups are not correlated with each other. There are two main types of Factor Analysis: EFA (Exploratory Factor Analysis) and CFA (Confirmatory Factor Analysis).