// model evaluation & validation · theory
Through the various model evaluation methods, we can find out how good our model is by comparing the predicted values with the actual values, but all this is done with the training dataset. The training dataset, however, can easily cause the model to overfit, giving us artificially good results when we perform the model evaluation methods. This can cause the model to crash and fail miserably when working with unseen data.
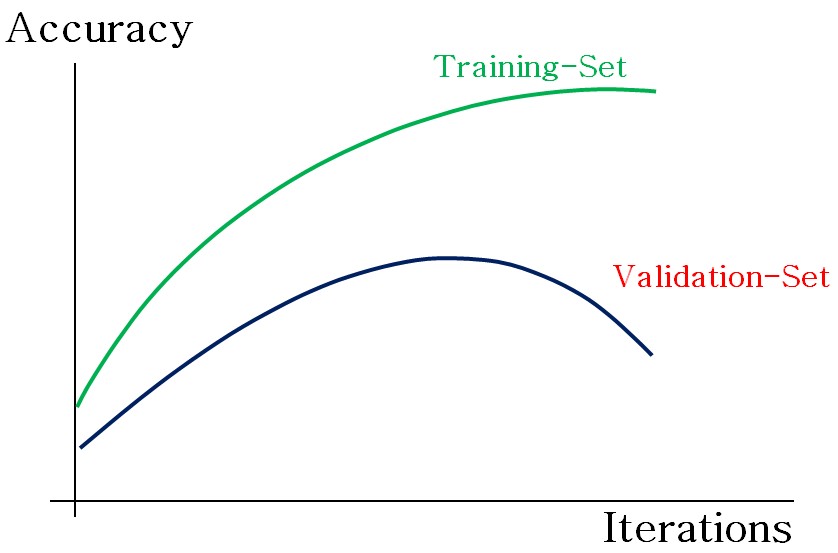
To mimic this process, we divide the original data so that we create our model on the training data, where we expect the model to perform reasonably well during model evaluation. As we also want the model to perform well on unseen data, we apply the model to data not used in its creation - the testing dataset - and it is the evaluation result from this dataset that matters. There are various ways of validating a model, among which the two most famous methods are Cross-Validation and Bootstrapping (Bootstrapping has been discussed under Ensemble Methods).
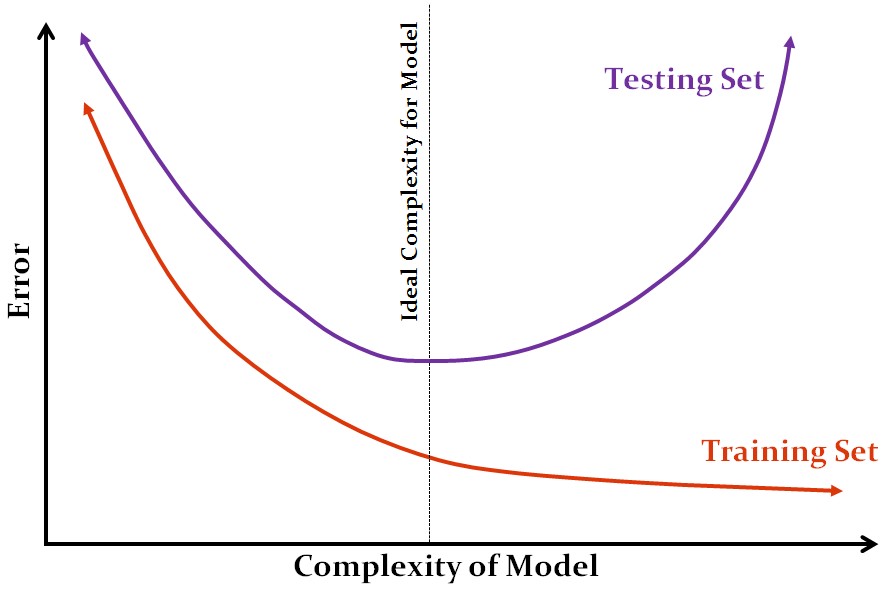
The idea ties back to the bias-variance trade-off: a function that is too complex fits the training data too well and overgeneralizes, causing it to fail on unseen data, while a function that is not complex enough underfits and fails to generalise. We therefore need to strike a balance between the complexity of the function, estimating the generalisation error - the error between the values predicted by the function and the actual values of unseen data.
Resampling (bootstrap or cross-validation) is done both to choose model tuning parameters and to estimate the model. As we are often required to perform both tasks simultaneously, this is done through double bootstrap or nested cross-validation, so that we end up finding the best model along with the best set of parameters that provides the minimum testing error. Below are two of the most common cross-validation methods used to validate models using random subsets of the data.
Known as "simple validation, rather than a simple or degenerate form of cross-validation", the Holdout method is the easiest way of performing a validation, where a portion of the data is left aside (known as the test data). Once the model is trained, it is evaluated based on its performance on this test data.
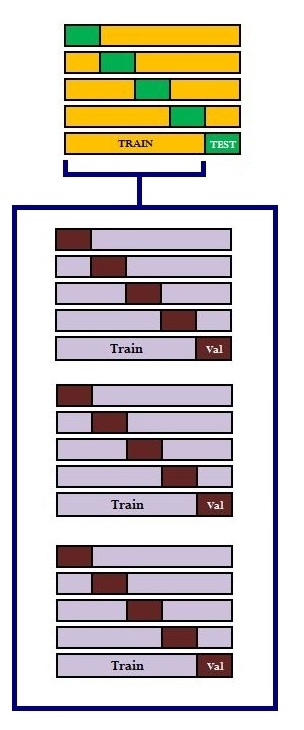
k-Fold Cross Validation is a method of using the same data points for creating both the training and testing dataset. As the data points should not overlap, and a data point can be used as either a training or a test point at a given time, we use k-fold cross validation, where we split the dataset into k parts, and in each iteration k-1 parts are used as the training dataset while the remaining part is used as the testing dataset. This process is repeated until all k parts have been used once as the test dataset.