// unsupervised learning · anomaly detection
Outliers can cause a lot of problems when implementing various kinds of learning algorithms, and various ways of handling outliers have been discussed under Outlier Treatment. However, there is a machine learning method known as Anomaly Detection that can be used to detect the outliers. Here the definition of outliers can be understood as the observations that are inconsistent with the majority of the remaining data. Therefore, here various machine learning algorithms try to find the observations that deviate from a bunch of observations, which can lead us to think that they might be outliers.

There are mainly three types of Anomaly Detection setups: Supervised, Semi-supervised and Unsupervised.
Supervised Anomaly Detection: This is very similar to classification problems discussed in the Supervised Modeling section. Here we have a well-labelled dataset where the Y variable is binary with one label indicating the outlier. Thus here we have labels for normal data and anomalous data. We then use various learning algorithms to learn a function or use some other method to find which kind of data is associated with an anomaly and, after due evaluation and validation, use this model to find anomalies in unseen data. Thus here generally the class associated with anomaly is very rare and all the supervised binary classification techniques can be applied here.
Semi-supervised Anomaly Detection: This method of anomaly detection is used when we have data where there are no anomalies. This data, which we know for sure is clean, can be used to learn some function where we at least know what non-anomalous data looks like. Thus we can use this model on an unclean dataset and identify the data that doesn't look similar to the data that we know is clean and classify them as anomalous. It is not as efficient as the Supervised method but is better than having nothing, which is the case with Unsupervised Anomaly Detection.
Unsupervised Anomaly Detection: This is the most common scenario people work with, where we have a dataset to work with and we don't have any particular domain knowledge to identify the outliers that the dataset might be containing. To find anomalies under such a setup is very tough as the data at hand can be good or it can in all possibility be bad and riddled with outliers, noise and anomalies. Here we can only presume that our data has a limited number of outliers and that something needs to be done before creating any kind of data model out of it. However, if the data is extremely unclean, say half of the data is an 'anomaly', then there is no way for us to identify it. For example, if we have a dataset which forms two clusters, then a data point away from these two clusters can be identified as an anomaly. However, if we have a lot of anomalies such that they end up making their own cluster, then it will become extremely difficult to detect them as outliers.
There are various kinds of Unsupervised Anomaly Detection methods such as Kernel Density Estimation, One-Class Support Vector Machines, Isolation Forests, Self Organising Maps, C Means (Fuzzy C Means), Local Outlier Factor, K-Means and Unsupervised Niche Clustering (UNC) etc. In the below-mentioned blog, methods such as Kernel Density Estimation, One-Class Support Vector Machines and Isolation Forests have been discussed.
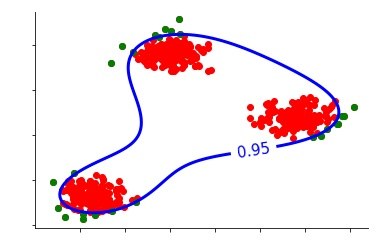
Different unsupervised learning models are explored in this blog that can be used to identify the anomalies. These anomalies can be considered as outliers and can be treated to make the data cleaner and more stable. Among the various kinds of unsupervised learning models, in this blog, Kernel Density Estimation, One-Class Support Vector Machine and Isolation Forests have been discussed, along with the effect of the various parameters used by these models for the identification of anomalies.