// modeling · theory
In the Unsupervised Learning setup, the algorithm is not explicitly instructed to predict something specific; rather, the patterns in the data are identified by the algorithm on its own and it is left for the user to interpret the output and come up with a conclusion.
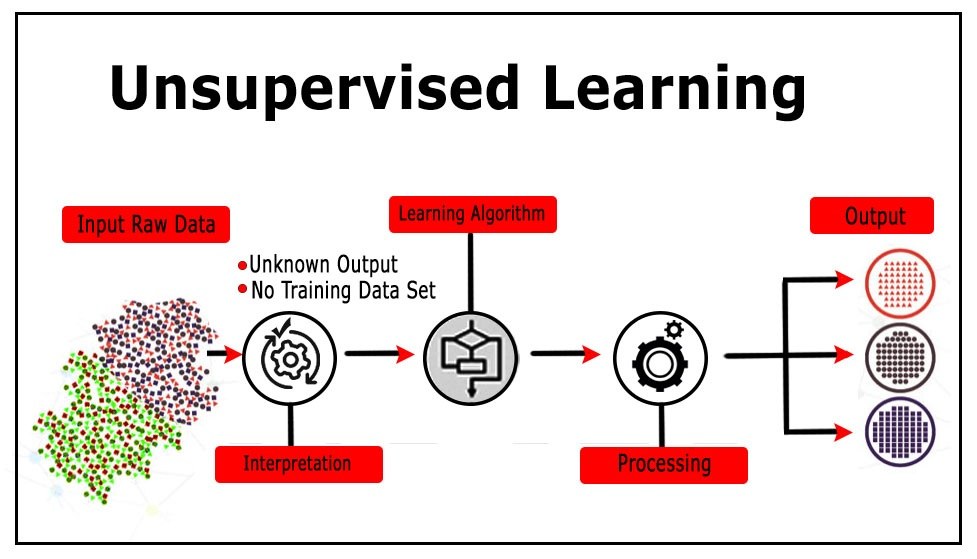
Unlike Supervised Learning, the data doesn't have a dependent variable having class labels. The biggest problem when working in this setup is that it becomes very tough to evaluate the performance of an algorithm, as in the absence of the class labels there is nothing to compare the output of the algorithm with. This poses the biggest challenge for the user when working with Unsupervised Learning algorithms, as the user has to see if the output is of any use and if it gives any important insights or not. Thus, unlike Supervised Learning algorithms, here there are no quantitative methods for evaluating the model's performance.
The most common tasks performed in the Unsupervised Learning setup are clustering, dimensionality reduction and anomaly detection (density estimation).
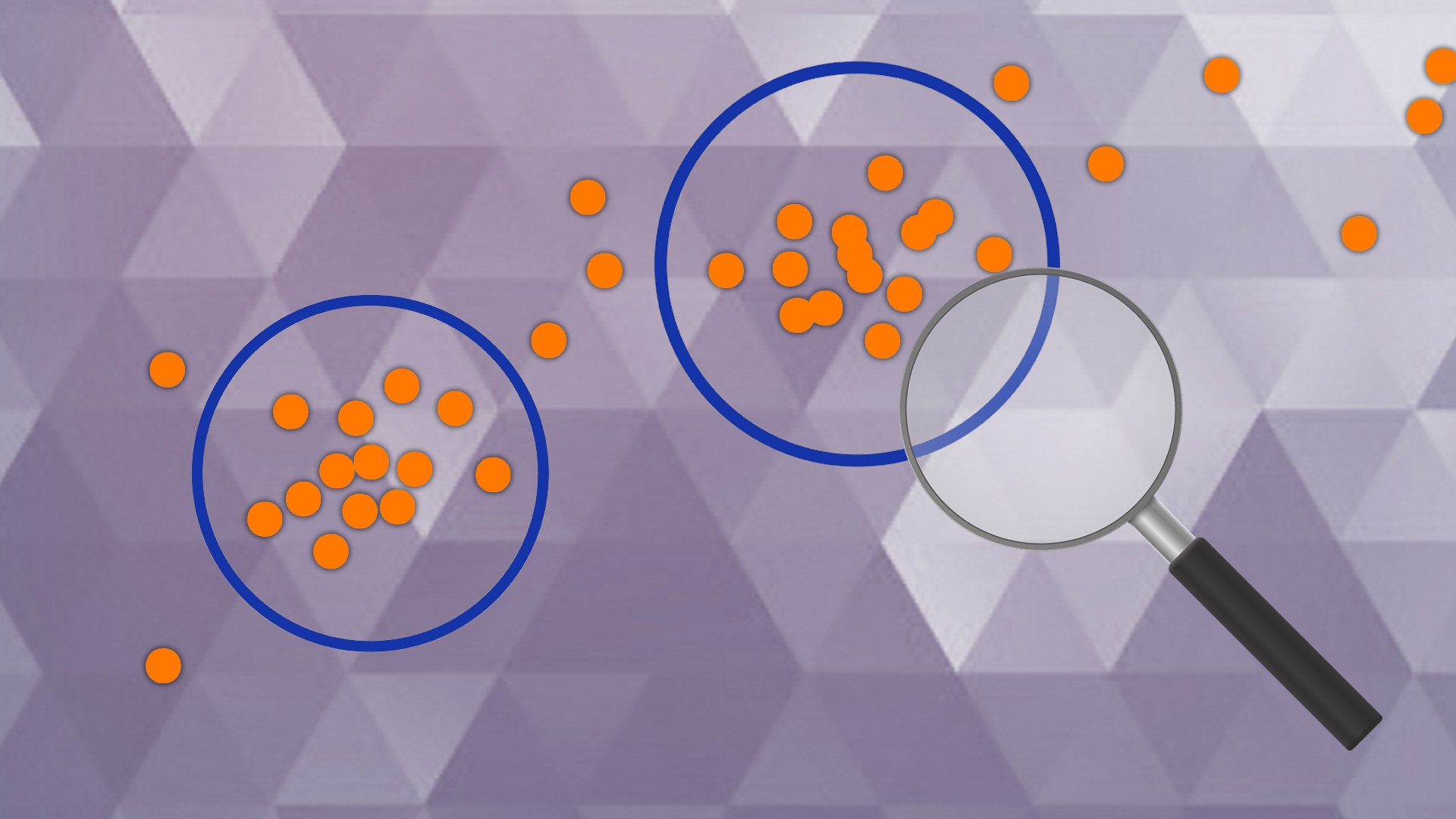
The most common problem which is solved in an Unsupervised Learning setup is clustering, where algorithms are used to find patterns in the data and come up with clusters of data points that are similar to each other in one way or the other. Among the most common clustering methods are K-Means, DBScan and Hierarchical Clustering.

The problem of multicollinearity gives rise to the biggest problem of data modeling, Overfitting. There are various algorithms which work in an unsupervised learning setup that help in reducing the dimensions of the data. Among them are Principal Component Analysis and Factor Analysis.

There are various density estimation and other methods which work in an unsupervised learning setup that are often used to identify the anomalies, which are then treated as outliers that help in cleaning the data. Among the most common Anomaly Detection algorithms are One-Class SVM, Kernel Density Estimation and Isolation Forest.