// modeling · theory
Supervised Learning is a setup of data modeling where we try to predict a particular kind of value. When working in a Supervised Learning environment, we have a labelled training dataset. A typical example of such data (for a classification learning algorithm) is a dataset having a dependent variable which has discrete values such as 'Spam' or 'Not Spam'. Here multiple independent variables are used to learn a function to help us determine the correct value of the dependent variable.
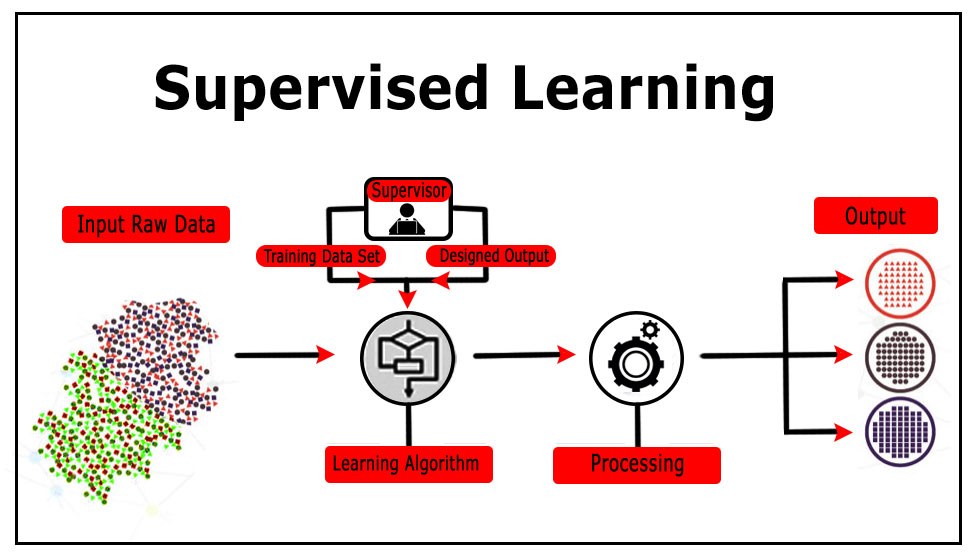
The biggest advantage of Supervised Learning is that the performance of the learning algorithm can be measured by comparing the predicted results with the original labels. Also, when working with a learning algorithm in a supervised learning environment, the accuracy of the model can be increased by tweaking the algorithm so that the output from the model can be close to the actual output.
Unlike Unsupervised Learning, the process of Supervised Learning typically involves a Training and Test dataset where the algorithms are made to learn a function by using a Train dataset and are evaluated using a Test dataset. The problems that can be solved in a Supervised Learning environment are Regression Problems and Classification Problems.

When the dependent variable contains continuous values and such continuous values are to be predicted, then such a problem is known as a Regression Problem. Here the output from the model is never essentially correct but is supposed to be near the original values. The most common learning algorithm for solving such a problem is Linear Regression, followed by Decision Trees, KNN etc.
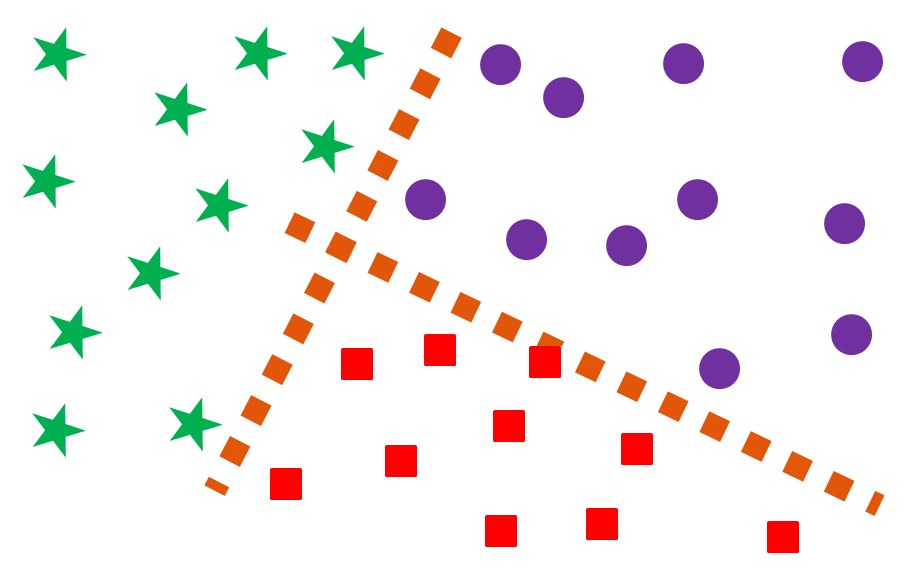
Under a classification problem, the dependent variable is discrete. Here the data has class labels and the challenge for the learning algorithm is to predict these class labels. The accuracy of the classification algorithm depends on the number of class labels that the model is able to identify correctly. Among the most common algorithms for a classification problem are Logistic Regression and Decision Trees, followed by other sophisticated methods such as Naive Bayes, SVM, KNN, ANN etc.