// unsupervised learning · clustering
Clustering is an example of unsupervised learning where we don't have a Y variable. As we don't have any Y variable, we don't try to predict anything. In Clustering, we simply try to explore our data by finding some patterns in it. Generally, these patterns lead to the number of different groups or types of data that might be present in the dataset. This way clustering can help us in determining the number of 'clusters' or 'sub-population' we have in our data, their size, and by further examining each of these clusters we can get to know the characteristics of these clusters. As mentioned in Anomaly Detection, clustering methods such as K-Means and Gaussian Mixture Models can be used to detect anomalies, i.e. outliers in the data.

Thus in clustering, nothing particular is instructed to the algorithm for prediction and, on the contrary, the algorithm runs and comes up with clusters of data that according to it are similar to each other. Unlike the algorithms discussed under the Supervised Learning setup, here the user has little control over the process of how and on what basis the clusters are being formed, and it is not used to predict anything in particular.
Clusters can be categorised in many ways. First, we have a family of clustering algorithms that are known as hard clustering, where each data point is assigned a cluster and it belongs to no other cluster but the assigned cluster. A soft clustering method, on the other hand, doesn't provide explicit clustering labels to the data points but provides a magnitude to which a data point belongs to a cluster. So, for example, a data point can belong 70% to cluster_1, 20% to cluster_2 and 10% to cluster_3. The other classification can be whether the clustering algorithm performs flat clustering or hierarchical clustering. Flat clustering simply partitions the data space in such a way that the data points end up belonging to different clusters. On the other hand, hierarchical clustering works a bit like a tree structure where each group of data can be further divided into subgroups, and such a subdivision can be done until the sub-groups stop making sense. For example, if we have a dataset and we perform hierarchical clustering and find two groups in our data, first is beverages and the other is solid fast food items, and we decide to further divide the groups, we may end up with a different set of groups where we know the different types of beverages (such as sodas, juice etc) and fast food items (burger, pizza, doughnut etc).
There are many other ways to classify the clustering algorithms, such as Hierarchical based methods, Partitioning based methods, Density-based methods, Grid-based methods and Model-based methods. The famous kinds of clustering algorithms are: Partitioning Based (K-Means, K-medoids, K-modes, K-D Trees, PAM, CLARANS, FCM); Hierarchical Based which can be agglomerative or divisive (BIRCH, CURE, ROCK, Chameleon, Echidna); Density-Based (DBScan, OPTICS, DBCKASD, DENCLUE); Grid-Based (Wave-Cluster, STING, CLIQUE, OptiGrid); Model-Based (EM, COBWEB, SOMs); and other methods such as Gaussian Mixture Models, Artificial Neural Networks and Genetic Algorithms.
Thus there are a lot of clustering algorithms that one can explore. Below, 3 types of clustering algorithms have been discussed: K-Means, Hierarchical Clustering and DBScan. It is very difficult to evaluate the performance of clustering algorithms. There are, however, manual techniques such as finding if the clusters make any sense or are close to expectations or not. Also, the size of the clusters can help in understanding the performance of the algorithm.

It is the most commonly used method of clustering. K-Means provides the user with the option of how many clusters are to be formed, which gives some sense of control and supervision in an otherwise unsupervised learning algorithm. K-Means uses centroids which are used to form clusters of data. In this method, the value of K plays the most crucial role.
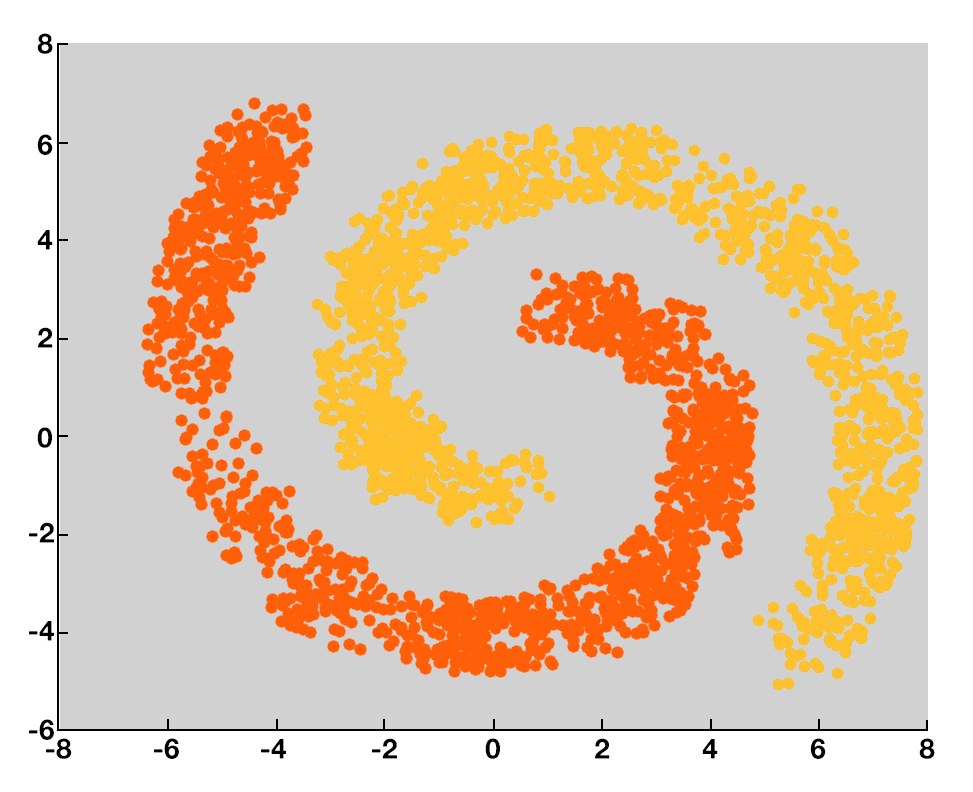
DBScan, also known as Density-Based Spatial Clustering of Applications with Noise, is a clustering technique which not only forms clusters but also identifies the outliers. Outliers often cause problems in other clustering algorithms such as K-Means etc, whereas DBScan can take care of them on its own. DBScan uses concepts such as Core Point, Border Point and Noise Point to come up with clusters.
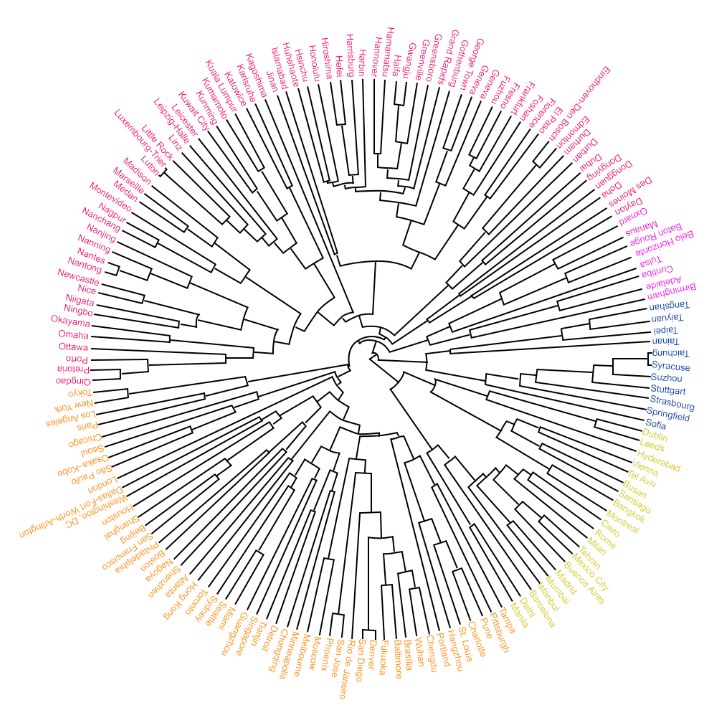
A Hard Clustering method, here the user doesn't pick a set number of clusters but rather the algorithm arranges the data in a hierarchy where on top of the hierarchy there is a single big cluster while at the bottom there are as many clusters as there are observations. Hierarchical clustering can follow two approaches, Agglomerative or Divisive Clustering.