// data exploration & preparation · feature engineering
Feature Engineering is a blanket term used for a bunch of activities performed on the features of the dataset making them more appropriate for their use in modeling. Feature Engineering can be challenging as it can often be very time consuming and may require some in-depth knowledge of the features one is dealing with.
The learning / modeling algorithms are highly dependent on how the features are presented and it becomes important to make the features compatible with the functioning of the algorithm. Feature Engineering involves the modification of features so that maximum information can be extracted out of them.
It is important to note that terms such as data mining, data exploration, data cleaning, feature engineering, data preparation can become confusing as the activities performed under each of them can overlap each other and thus some may consider feature scaling or feature selection, not as part of feature engineering etc. However, in this section, feature transformation, feature scaling, feature construction and feature reduction are considered as a part of feature engineering.
Feature Scaling methods are used to make the features to be on the same scale. Scaling is particularly important for those algorithms that use some distance metric for their functioning. Feature Transformation, on the other hand, is used when the features cannot be directly used due to the data being skewed or non-linear and thus requires some transformation.
Feature Construction deals with the methods of creating new features from a set of existing features that can help in boosting the predictive capabilities of the models.
Feature Reduction is in a way the opposite of Feature Construction where we reduce the number of features through various methods. It is important to reduce the number of features as for certain algorithms, too many features can adversely affect the performance of the model and thus feature selection methods are applied.
These four aspects of feature engineering are discussed in the following blogs.
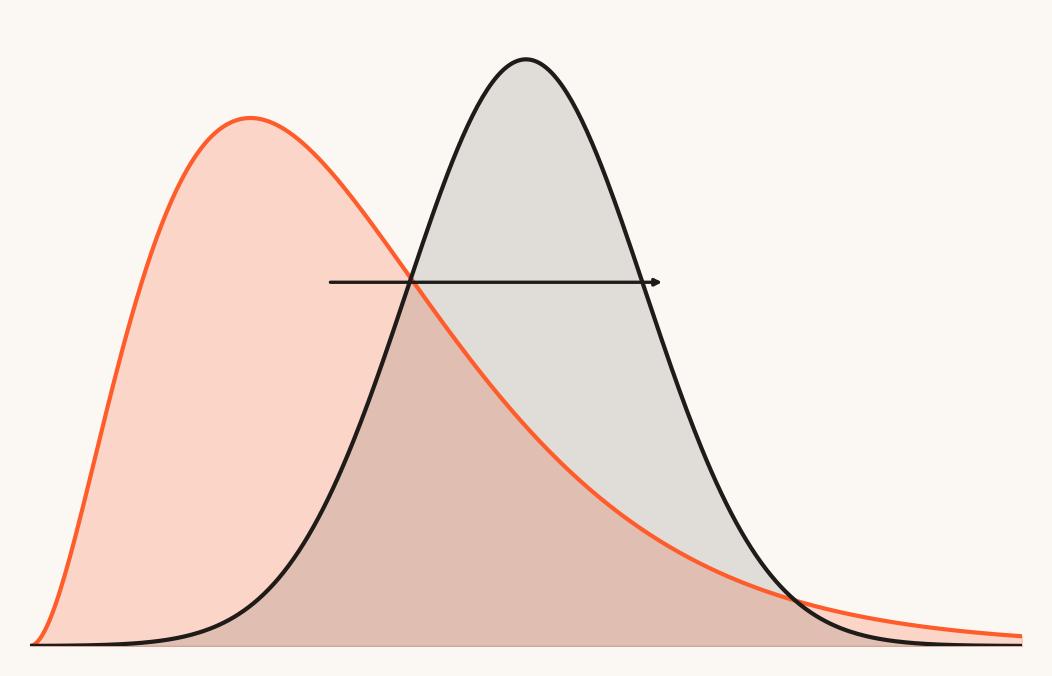
The method for transforming a feature is by replacing the observations of the feature by a function. This is done mostly to transform the relationship that an independent feature has with the dependent variable. Often the transformation is done to change this relationship from non-linear to linear. Also, transformations are done when the data is skewed and there is a need to make the distribution normal. Methods of Transformation include the use of Logarithm, Square Root, Cube Root, Arcsine square root etc.

When the features are required to be on the same scale, feature scaling is performed. In various algorithms, feature scaling prevents them from giving greater weightage to certain features while for the algorithms such as K means which use distance metric such as Euclidean distance for their functioning, having features on the same scale becomes very important. For the correct functioning of Optimization techniques such as Gradient Descent or for feature extraction techniques such as Principal Component Analysis, the features are required to be scaled. The method of feature scaling includes Normalisation where the values of the features are made to range between 0 and 1 or -1 and 1. Other important methods include Z score normalization.

There are multiple ways and reasons for constructing features. Methods such as encoding are used to create new numerical features from the existing categorical features. This helps in using such features in the algorithms where categorical features cannot be considered. On the other hand, there are derived variables where by using a combination of features, we come up with a new set of features that are able to provide us with more information. Binning is another concept under feature construction where new categorical features are created, either by converting a numerical feature into categorical bins or by grouping a categorical feature that has many categories into fewer categories (which helps control the curse of dimensionality that one-hot encoding can introduce).

The problem of multicollinearity gives rise to one of the biggest problems of data modeling- Overfitting. The reason for multicollinearity is having correlated features. Various methods are developed to find such variables and get rid of them. The two broad themes that run under the feature reduction are feature selection and feature extraction. Feature Selection methods simply pick the relevant, unique set of features that can control the problem overfitting whereas Feature Extraction doesn't follow an 'in or out' approach and rather aims at extracting maximum information from all the features. Thus, unlike feature selection, it doesn't eliminate features rather it transforms the feature space to extract the uncorrelated components. Other grouping techniques such as Factor Analysis can also be used for feature reduction.