// supervised learning · classification
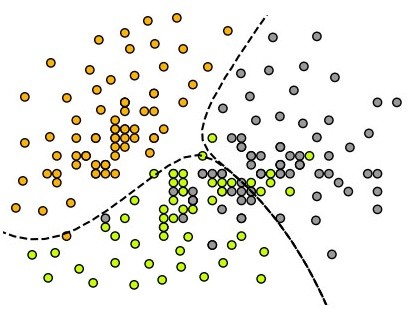
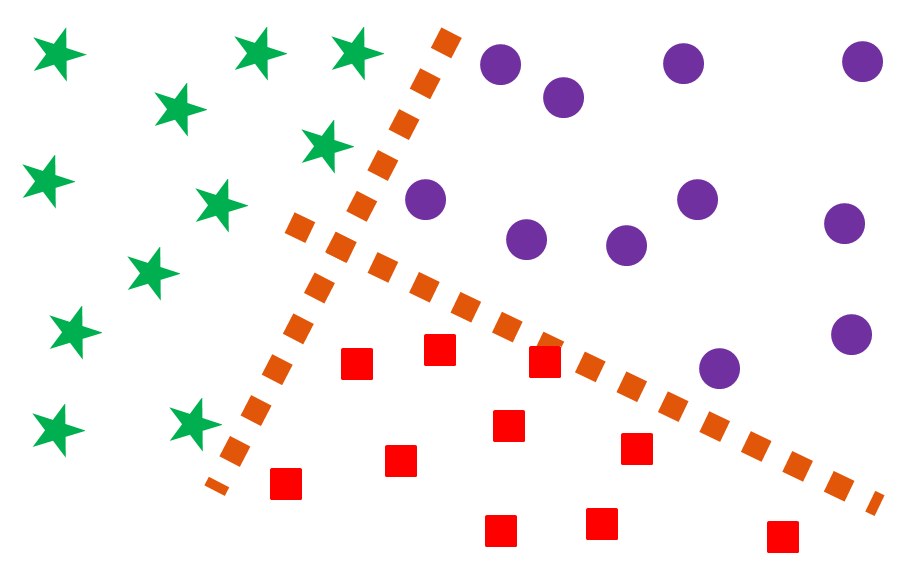
Among the most common prediction problems is classification, where the data has a dependent variable which has clear-cut distinct categories that the model needs to predict. Here most of the algorithms learn a function to come up with a decision boundary which helps in classifying the data, providing them with separate class labels.
The 'settings' of the algorithms are often constantly 'updated' and various techniques are used to reduce the errors, where an error is a misclassification which means assigning a wrong data label to a data point.
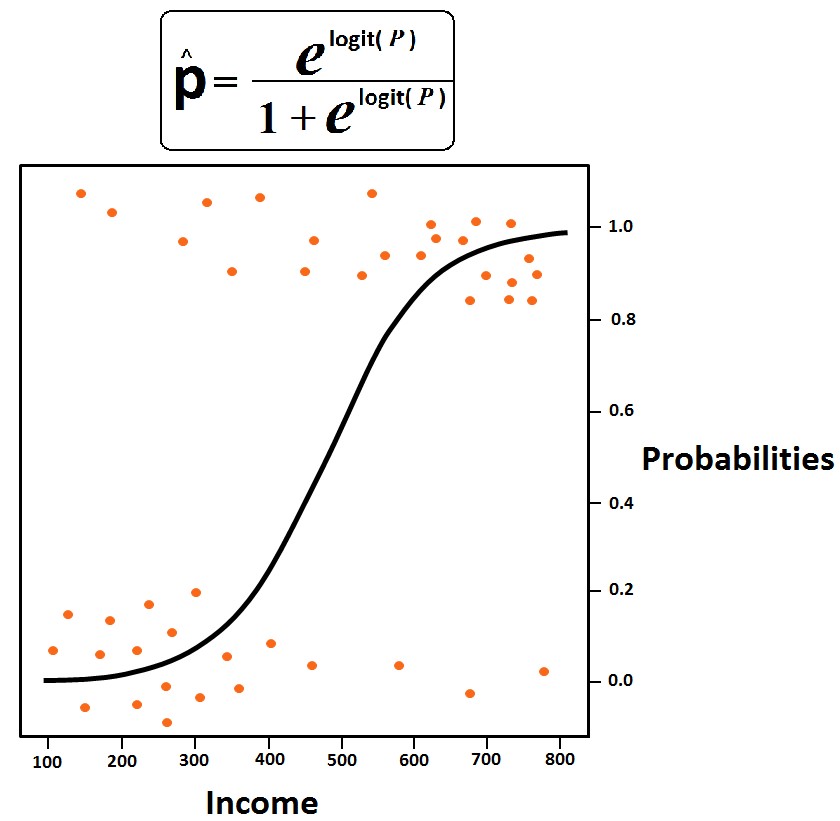
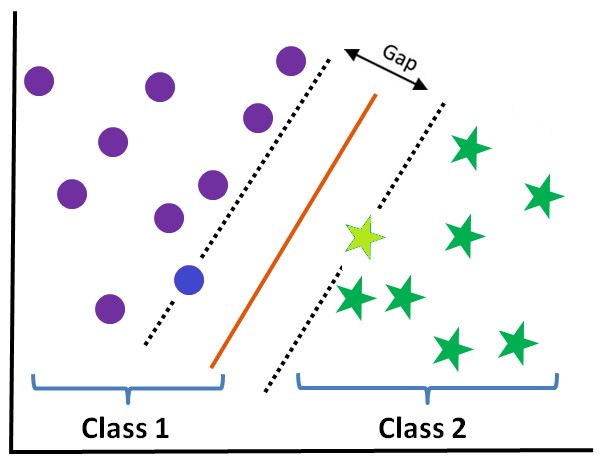
The most common learning algorithm is Logistic Regression which is a Linear Supervised Learning algorithm. A Linear Classification algorithm is where the dependent variable is classified on the basis of a linear combination of the independent variable. Here the decision boundary is a line or a hyperplane, which is a straight line in the data space that divides the data points classifying the data. Regularized Logistic Regression is also used which addresses the issue of overfitting. Other sophisticated Linear classification algorithms are SVM, Naive Bayes etc.
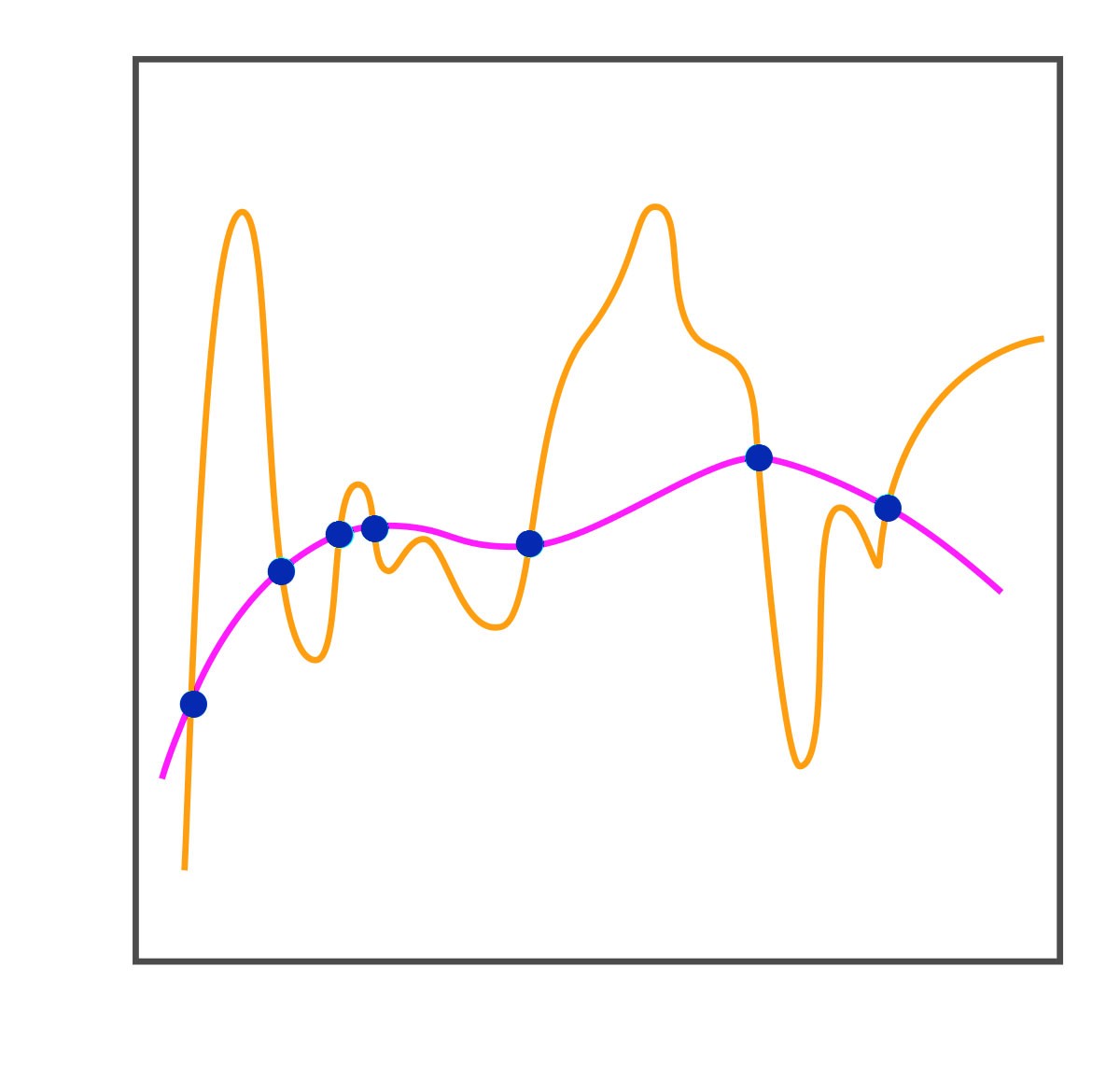
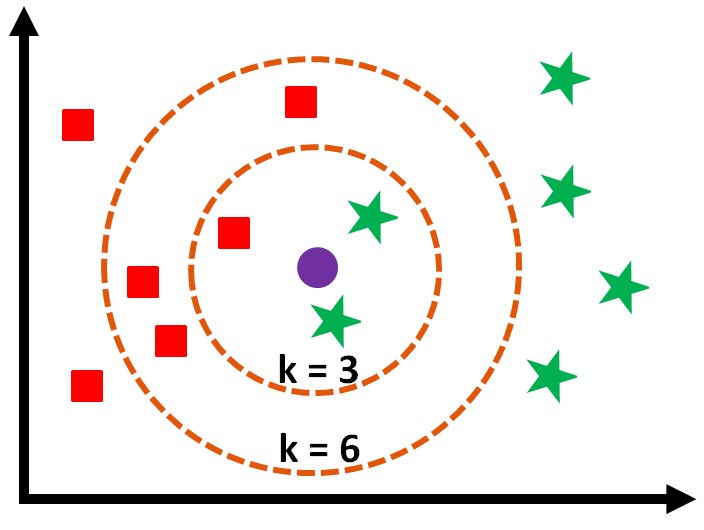
There are various non-linear classification methods also, such as the instance based KNN and ANN, which are trained in a Supervised Learning setup using Backpropagation. (Neural networks can also be used in Reinforcement Learning, where the model improves by trial and error from a reward signal rather than from labelled data; but the ANN used here for classification is supervised.) In these algorithms the decision boundary is non-linear.
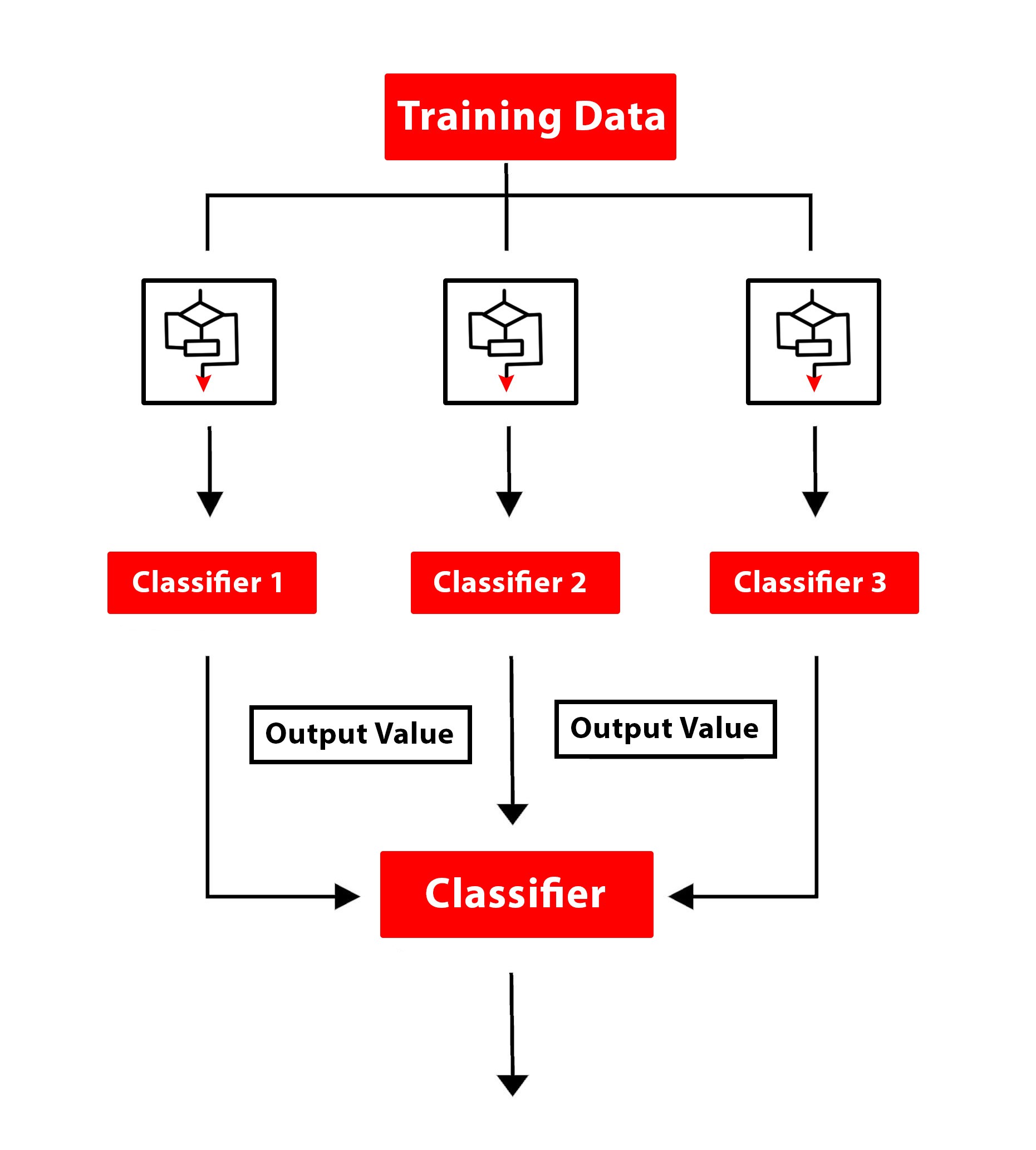
In addition to these, various ensemble methods such as Bagging, Boosting and Stacking can also be used for solving classification problems, which use multiple algorithms and resampling methods to come up with more robust results.
Machine Learning algorithms used only for Classification Problems