// feature engineering · feature reduction
In recent times, the amount of data being generated has exploded and this has given rise to more sophisticated models and better accuracy. Often, the amount of data that one gets can be overwhelming with a lot of features, making the task of data exploration very tough.
The high amount of data has its own disadvantages such as it increases the computational time, decreases the storage and, most importantly, causes multicollinearity causing the models to overfit. These problems have led to the development of various dimensionality reduction techniques.
Feature Reduction, also known as Dimensionality Reduction, helps us in reducing the processing time, allowing us to perform more complex algorithms. Another benefit of having a low number of features is that it frees storage space. The most important benefit of Feature Reduction is that it takes care of the problem of multicollinearity.
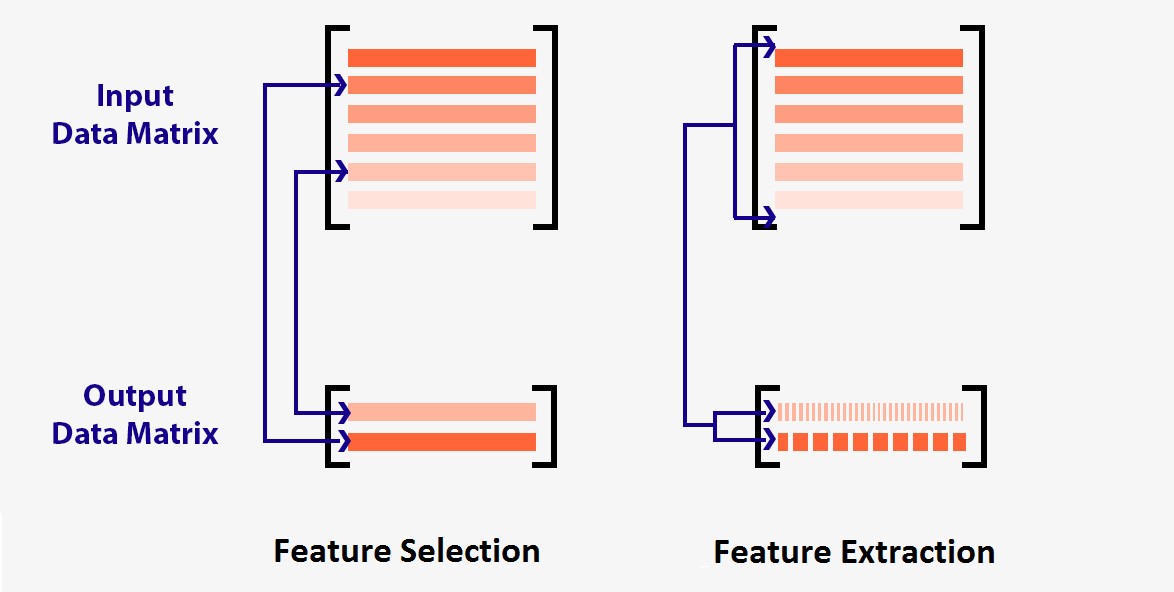
The techniques of feature reduction can be divided into two types: Feature Selection and Feature Extraction. Under Feature Selection we check the worthiness of a feature by using different techniques, and once the features that are less useful to our model are identified, they can be dropped from the dataset. Among the most common methods of Feature Extraction is Principal Component Analysis, where the data from high dimensional space is reduced to lower dimensions.
The basic difference between the two methods is that while in feature selection the target variable is taken into consideration and the methods work in a supervised environment where ultimately the features are dropped to reduce the number of features, the method of feature extraction is inherently different: rather, the variance of all the features is extracted and a new set of 'artificial features' is created that has most of the variance found in the original set of features.
We can also use grouping methods, and one of the most common such methods used for feature reduction is Factor Analysis, where the features are grouped based on their similarity which is determined by their shared variance, and then the user can pick relevant features from these groups making the feature set unique and less vulnerable to multicollinearity.
All such methods are explored in the following blogs.
In this section, the multiple ways of selecting the appropriate features are explored. A good amount of feature selection methods can be grouped into three types: Filter Methods, Wrapper Methods and Embedded Methods. Filter Methods are independent of the algorithm where the features are selected on the basis of the interactions among the features, whereas Wrapper Methods, unlike filter methods, are not a pre-processing step and the learning algorithm plays an important role. The Embedded Method uses various regularization techniques to select features.
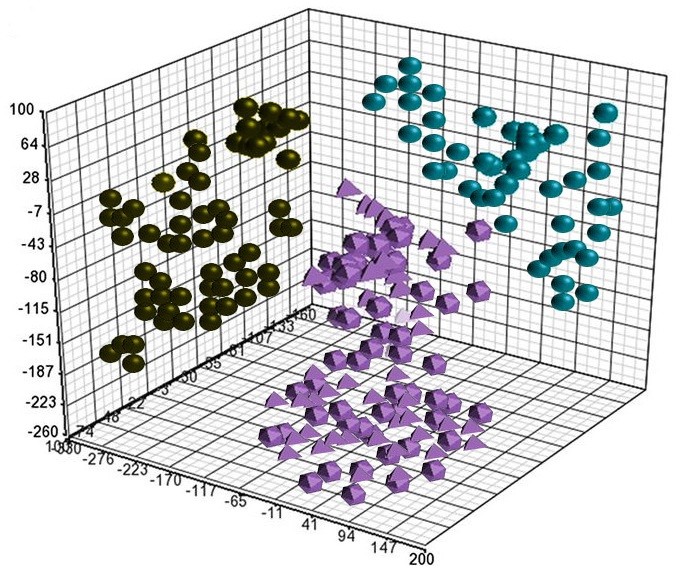
There are various methods of performing feature extraction such as Principal Component Analysis, Kernel PCA, Linear Discriminant Analysis (LDA), Independent Component Analysis etc. In this blog post, PCA is explored. In this method, features are transformed into a set of 'artificial features'. These 'artificial features' are known as Principal Components, where the first component contains most of the information that can be contained in a single 'artificial feature' and we are left to select the number of components in order to reduce the features.
Correlation Coefficient plays an important role in Factor Analysis. A variable-grouping technique, Factor Analysis can be used as a feature selection method. Here groups are created by combining highly correlated features where the groups are not correlated with each other. There are two main types of Factor Analysis: EFA (Exploratory Factor Analysis) and CFA (Confirmatory Factor Analysis). In this blog, factor analysis used as a feature selection method is explored.