// feature reduction · feature selection
Dimensionality reduction is the process of reducing the number of variables (features) in review. The reduction of features is required due to the curse of dimensionality as many modelling algorithms don't work properly in high dimensions. Also, fewer features help in reducing overfitting and thus help in increasing the model's accuracy.
Dimensionality Reduction can be divided into 2 sub-categories: Feature Selection and Feature Extraction. In this section, Feature Selection is explored.
An intuitive idea about how feature selection is different from feature extraction can be, for example, we have a linear equation: a+b+c+d=e. Imagine if a, b, c and d represents the independent features while e represents the target variable and we have to reduce the number of independent features then we can do it in two ways.
First, we can equate ab = a+b and can use ab to represent two variables making the new equation to look like ab+c+d=e. This is how feature extraction works.
However, if the value of d is 0 or is a very small number making it irrelevant to the equation, then it can be dropped making the equation to look like a+b+c=e. This is how feature selection works as we select only those variables that are relevant to our 'equation' and leave out the irrelevant features. Thus Feature selection drops the variables that are irrelevant and selects the features that increase the model's accuracy.
In the below blogs, various methods through which we can select the important features are explored. There are mainly three methods in which Feature selection can be done. They are Filter Methods, Wrapper Methods and Embedded Methods.
Wrapper methods use predictive models to score feature subsets based on the error rate of the model. The drawback is that they are computationally intensive but they produce the best results providing us with the features that help in increasing the accuracy of our model.
Filter Methods are less computationally intensive but are also less accurate when compared to Wrapper Methods. They are also unique in the sense that they produce a set of features that don't contain assumptions based on the predictive model making it a useful method to find certain relationships between features such as which combination of features decreases the model's accuracy and which combination of features help in increasing the model's accuracy.
Embedded method mostly uses various regularization algorithms where it finds the features that contribute towards the accuracy of the model during the model building process only. Thus it picks features in each step of the model building process thereby picking features till it reaches the highest accuracy.
All these methods have been explored below.
Various Inferential Statistics are used in Filter Methods to reduce the number of features. For reducing numerical features, Correlation Coefficients can be used to find the correlation between the various independent variables and the dependent variable. Variants of Correlation Coefficient such as MIC can also be used here. For Categorical Features, chi-square can be used. Other methods include Linear Discriminant Analysis (LDA). However, all such methods are very time consuming as each feature needs to be analyzed separately making the whole process of feature selection slow.
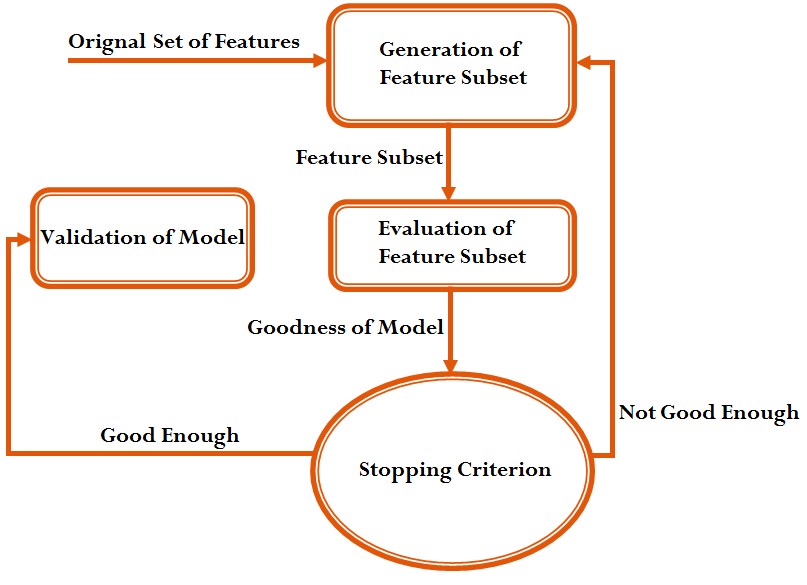
Models can be used to reduce the number of features and this is what is done in the different wrapper methods. Among the most common wrapper methods is the Standard Stepwise method which is a combination of Forward Selection and Backward Selection method. Here unlike Filter methods, all the features of the dataset can be considered in a single go with much less human intervention making the whole process of feature reduction quicker and more reliable. Other methods include Recursive feature elimination and Stability Selection.
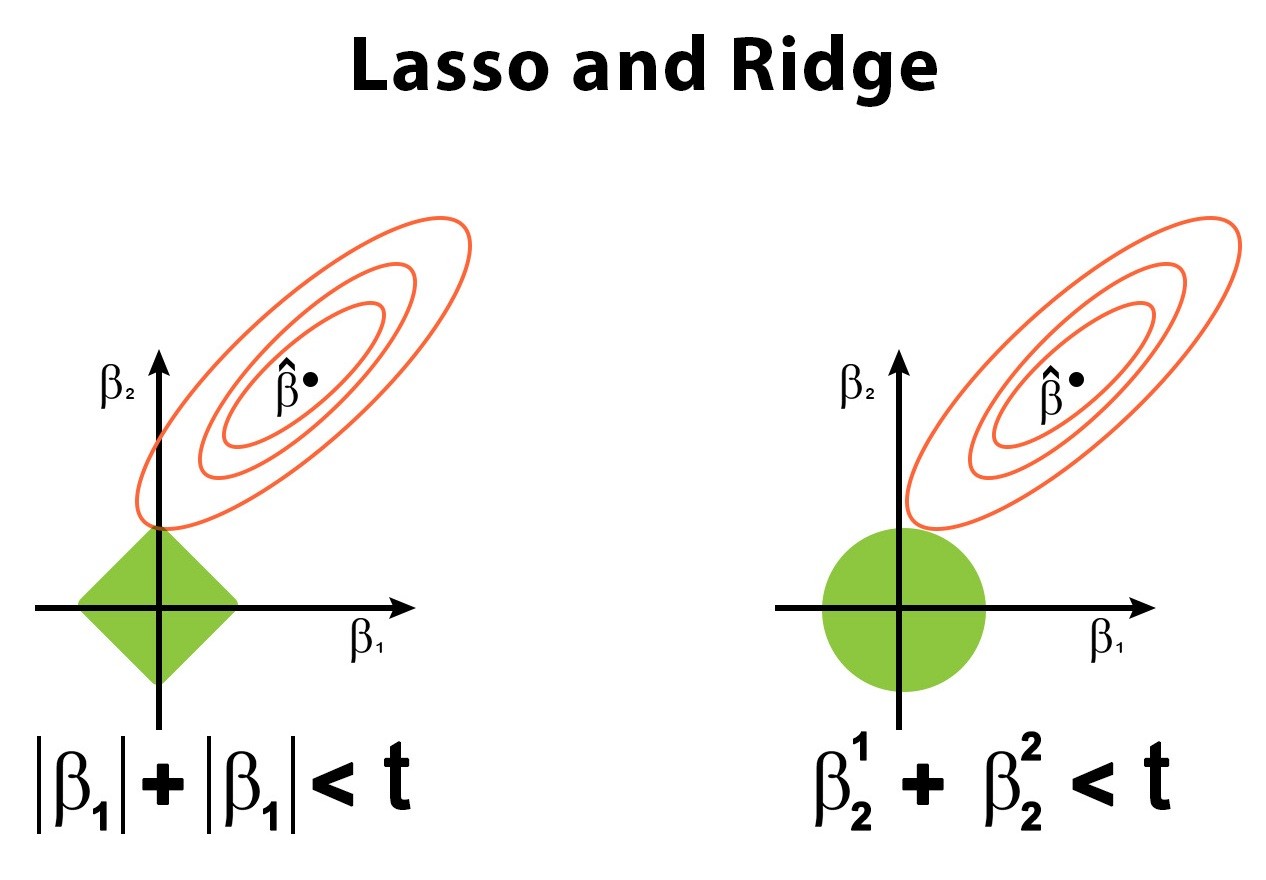
Under the Embedded method, different regularization methods are used. The most common methods are Ridge Regression and Lasso Regression. In Ridge, L2 regularization is used forcing coefficient values to be spread out more equally. This way the features having less coefficient value can be dropped. Ridge doesn't make any coefficient to shrink to the extent that it becomes 0 and this is where it differs from Lasso which uses L1 regularization providing certain features to have 0 as coefficients. This way the features having non-zero coefficient can be selected.