// model validation
Holdout Cross-Validation
Before understanding the various methods of Cross-Validation, it will be useful to go through the following excerpt from the article about cross-validation on Wikipedia:
Cross-Validation is the process of assessing how the results of a statistical analysis will generalise to an independent dataset. In a prediction problem, a model is usually given a dataset of known data on which training is run (training dataset), and a dataset of unknown data (or first seen data) against which the model is tested (called the validation dataset or testing set). The goal of cross-validation is to define a dataset to “test” the model in the training phase (i.e., the validation set), in order to limit problems like overfitting, and to give an insight on how the model will generalise to an independent dataset.
Two types of cross-validation can be distinguished, exhaustive and non-exhaustive cross-validation. Exhaustive cross-validation methods are cross-validation methods which learn and test on all possible ways to divide the original sample into a training and a validation set, such as Leave-p-out cross-validation and Leave-one-out cross-validation. Non-exhaustive cross-validation methods do not compute all ways of splitting the original sample. Methods of non-exhaustive cross-validation include the Holdout method and k-fold cross-validation.
Holdout Method
This is the classic “simplest kind of cross-validation”. This method is often classified as a type of “simple validation, rather than a simple or degenerate form of cross-validation”. In this method, we randomly divide our data into two: Training and Test/Validation set, i.e. a hold-out set. We then train the model on the training dataset and evaluate the model on the Test/Validation dataset. The model evaluation technique used on the validation dataset to compute the error depends on the kind of problem we are working with - methods such as MSE being used for Regression problems, while various metrics providing the misclassification rate help in finding the error for classification problems. Typically the training dataset is bigger than the hold-out dataset. Typical ratios used for splitting the dataset include 60:40, 80:20 etc. This method is only used when we have just one model to evaluate and no hyperparameters to tune.
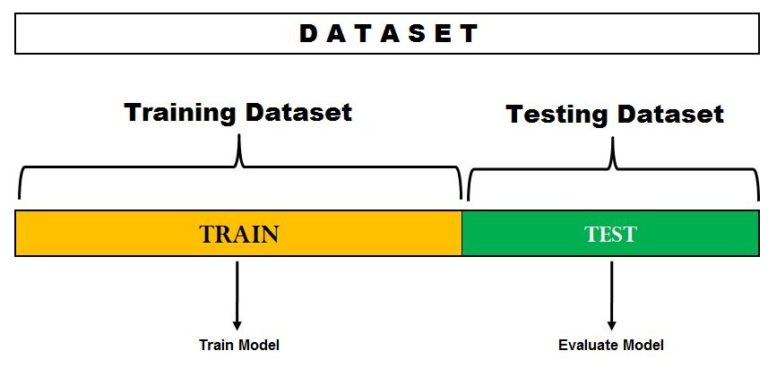
The limitation of such a method is that the error found in the test dataset can highly depend on the observations included in the train and test dataset. Also, if the train or test dataset are not able to represent the actual complete data, then the results from the test set can be skewed. This method is not effective for comparing multiple models and tuning their hyperparameters, which leads us to another very popular form of the hold-out method - one which includes splitting the data into not two, but three separate sets. Here we divide the training dataset into a training and a validation set, thus dividing the original dataset into Training, Validation and Test sets.
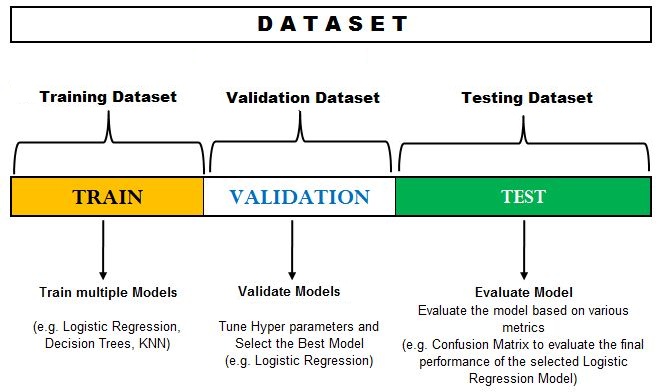
The typical steps to execute model validation here include training the model, or commonly multiple models, on the training set. The validation set, which is a hold-out set from the training set (i.e. a portion of the training set kept aside), is then used to optimize the hyperparameters of the models and evaluate them. Thus the validation set is used to tune the various hyperparameters and select the best performing algorithm. However, to fully determine that the selected algorithm is correct, we apply the model to the test dataset. This is done because, as we tune the hyperparameters based on the validation set, we end up slightly overfitting our model to the validation set. Thus the accuracy we receive from the validation set is not considered final, and another hold-out dataset - the test dataset - is used to evaluate the final selected model, and the error found here is considered the generalisation error.
Why Cross-Validation Matters
Cross-validation is a very important aspect of data modeling and should be used especially when the data at hand is limited. This way we are able to get accurate results even with limited data, and can save our model from overfitting while obtaining a more accurate estimate of the model's prediction performance. In this section, we have only discussed the Holdout method, which is not enough, as we need a more advanced validation technique that can be more unbiased and can save the model from overfitting - and such a technique is k-fold cross-validation, which is explored next.