// model validation
K-Fold Cross-Validation
Before understanding the various methods of Cross-Validation, it will be useful to go through the following excerpt from the article about cross-validation on Wikipedia:
Cross-Validation is the process of assessing how the results of a statistical analysis will generalise to an independent dataset. In a prediction problem, a model is usually given a dataset of known data on which training is run (training dataset), and a dataset of unknown data (or first seen data) against which the model is tested (called the validation dataset or testing set). The goal of cross-validation is to define a dataset to “test” the model in the training phase (i.e., the validation set), in order to limit problems like overfitting, and to give an insight on how the model will generalise to an independent dataset.
Two types of cross-validation can be distinguished, exhaustive and non-exhaustive cross-validation. Exhaustive cross-validation methods are cross-validation methods which learn and test on all possible ways to divide the original sample into a training and a validation set, such as Leave-p-out cross-validation and Leave-one-out cross-validation. Non-exhaustive cross-validation methods do not compute all ways of splitting the original sample. Methods of non-exhaustive cross-validation include the Holdout method and k-fold cross-validation.
K-Fold Cross-Validation
K-Fold Cross-Validation is a method of using the same data points for training as well as testing. To understand the need for K-Fold Cross-Validation, it is important to understand that we have two conflicting objectives when we try to sample a train and test set. On one hand, we want to create a test set which is as big as possible, so the chances of the testing error converging with the generalisation error increases, thus providing us with the actual picture of how our model will perform with unseen data. At the same time we also want our model to be as accurate as possible, for which we need a lot of training data in order for the model to go through as many scenarios as possible that can be there in the unseen data, so it learns an effective function that can appropriately generalise and perform well with the test/unseen data. However, we have a limited amount of data, and the training and testing datasets cannot overlap each other. Thus we can either go for a splitting ratio that favours the training set, such as 60:40, or a ratio that favours the test set, such as 40:60, or go for a more neutral ratio of 50:50. However, they all limit the data that we have at our disposal.
This problem can be solved through k-fold cross-validation. In k-fold validation, the value of k can be determined by us. To understand k-fold validation we first consider k=2.
For example, we have a dataset and we decide a splitting ratio of 50:50. Now we have subset-A, which is one half of the data and can be considered as the training dataset, while subset-B, the other half of the whole dataset, can be considered as the testing dataset. We then fit the model on the training dataset and evaluate the model on the testing dataset. We then reiterate the process, but this time subset-B is considered as the training set and subset-A is considered as the testing set. Now we train the model on subset-B and compute the error (evaluate the model) on subset-A. We then average the two results and consider this value as our generalisation error. It is important to understand that in each “fold”, i.e. in each step, each observation is considered as either train or test, and thus no overlapping between the train and test sets takes place.
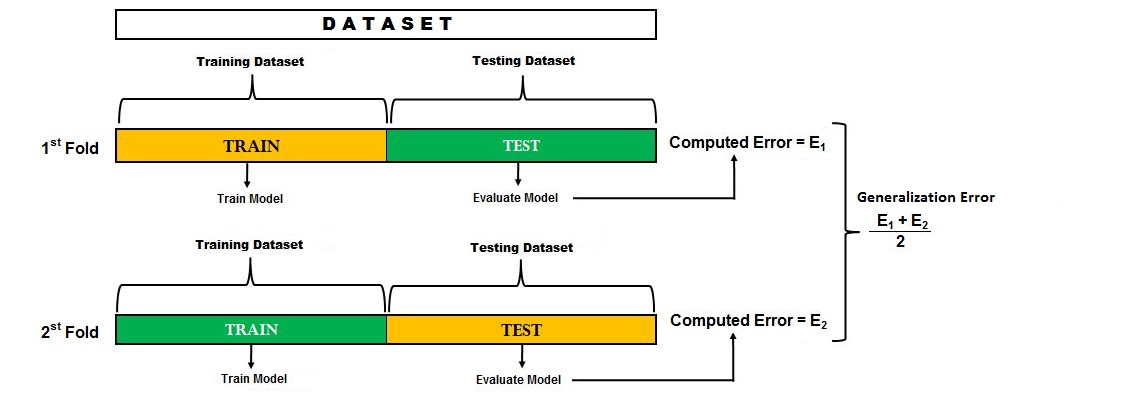
In reality, the chosen values of k are much higher than two, where we randomly divide the dataset into k equal sized parts, leave out one part k, and fit the model on the other combined k-1 parts. We then evaluate the model on the left-out k part, and this process is repeated k times so that each part is used as the testing set. The results from each fold are then combined and averaged to come up with the final error. For example, if we choose the value of k to be 5, then we will have 5 iterations wherein each iteration, the whole dataset is divided into 5 equal parts, and the model is trained on 4 parts and evaluated on the fifth part. The same is done in each other iteration also, with the exception of the testing set, which will belong to a different part each time. This way we are able to reduce the bias and variance such that the model doesn't overfit or underfit.
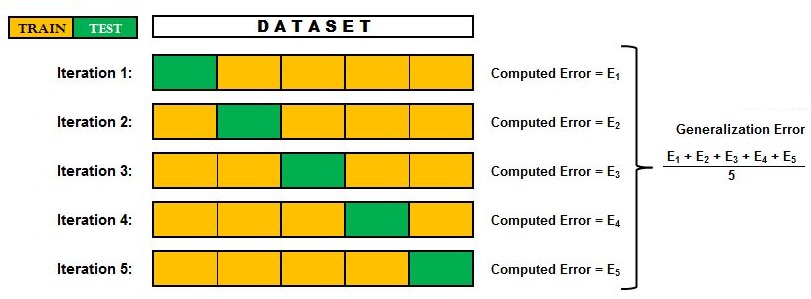
If we have more than one model - for example, three models to validate: Logistic Regression, Decision Trees and KNN - then the above step will run separately for each of these models. Thus we will have 3 × 5 iterations, and we will have 3 generalisation errors to choose from.
As mentioned earlier, we want to use the validation techniques not only to find the best model but also to optimize the hyperparameters. We can understand this with an example.
We are dealing with a binary classification problem. We have three models - KNN, Decision Trees and Support Vector Machines - and we want to know the best model for our data, made up of 10,000 samples. We also need to tune hyperparameters, such as K for KNN, C for Support Vector Machines and Depth of Trees for Decision Trees. Let us start with KNN, where we have the hyperparameter K with possible values of 3, 4 and 5. We begin by setting the value of K (hyperparameter) at 3. We perform k-fold cross-validation with k=5 and split the data into 5 folds. Then we perform 5 iterations wherein each iteration, we train the KNN model (with hyperparameter K being 3) on the combined k-1 parts and evaluate the model on the remaining fold. We do this for four more iterations so that each fold has once been considered the test set. All the results produced from these 5 iterations are then averaged, and we get the result for the value of hyperparameter K=3. We then repeat the whole process with the value of hyperparameter K being 4, and then again with K being 5. (Do not confuse K with k - K is the hyperparameter of KNN, while k stands for the value of k in k-fold cross-validation.) We then compare these 3 results and choose the best value of K for KNN. As we have two more models, we perform all the above-mentioned steps for each value of their hyperparameters. Thus if we have to choose from C=1, 2 and 3 (SVM), K=3, 4 and 5 (KNN), and Depth of Trees=6, 7 and 8 (Decision Trees), then we will have 9 generalisation error values, and we will select the one that provides us with the minimum error. This way we not only select the best hyperparameter and model, but also evaluate the best model.
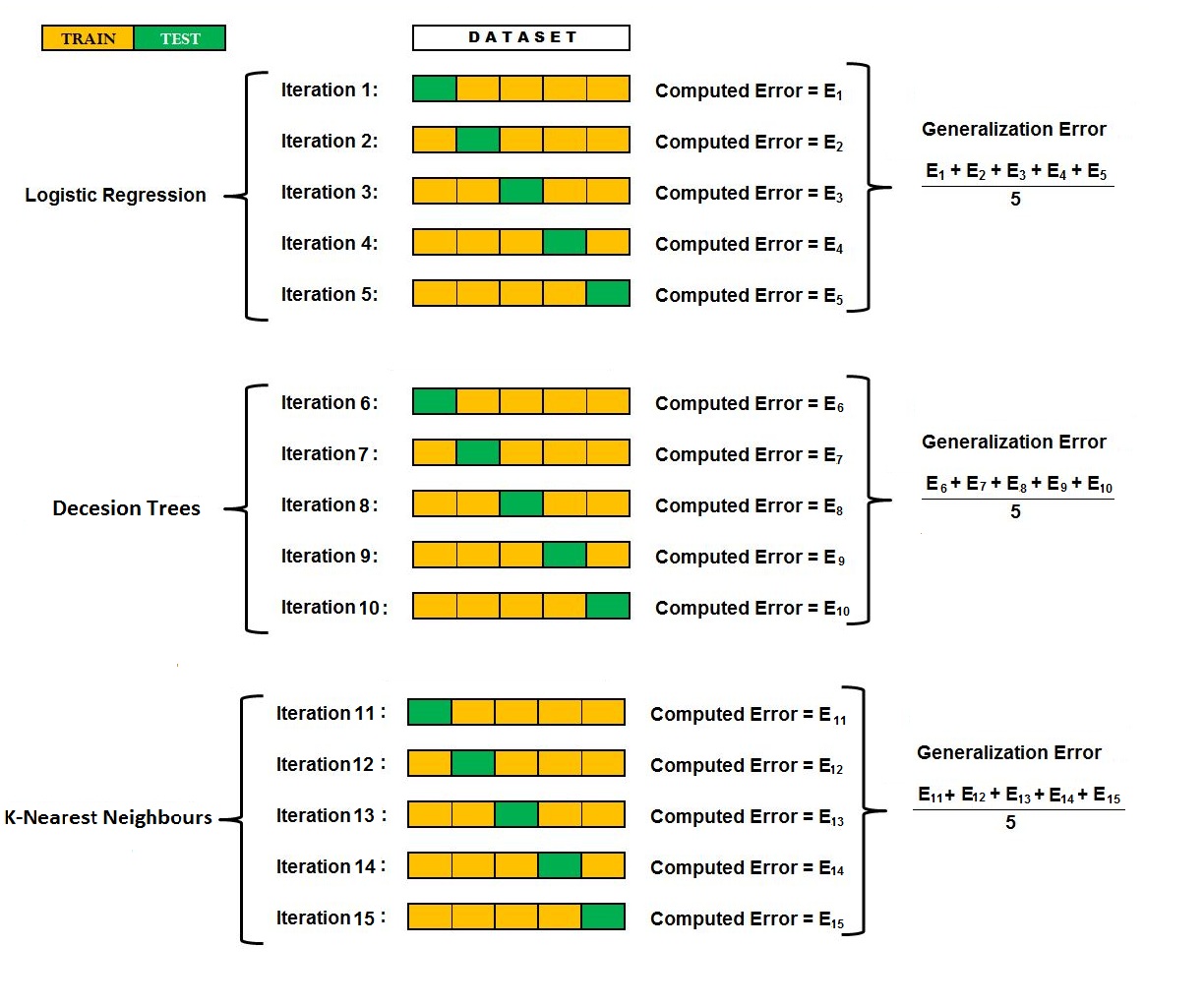
However, this method has a potential problem. As we are using the same test set to optimize the parameters as well as evaluate the selected model, we make the model vulnerable to overfitting, as our model evaluation can be biased and show “artificially good results”. Thus the test set used to select the hyperparameters and model cannot be used to evaluate the final model. This leads us to use nested cross-validation. It is advised to go through the 2010 paper written by Cawley and Talbot for further analysis of this issue.
Nested K-Fold Cross-Validation
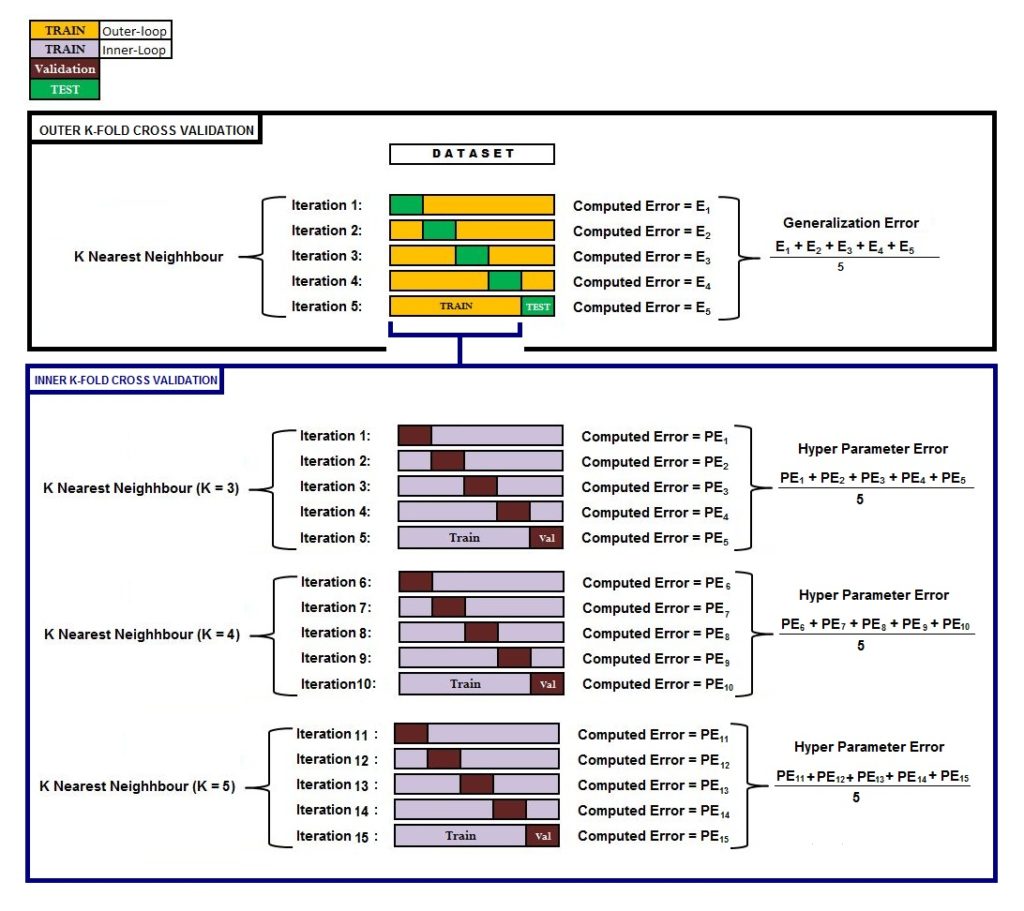
We discussed in the Holdout Cross-Validation section that splitting the data into train and test is not sufficient, and splitting the data into train, validation and test is more effective in order to produce more unbiased results. Nested cross-validation uses this concept, where it uses a series of train, validation and test splits. In nested cross-validation, we have an inner k-fold cross-validation that is equivalent to the train-validation partition, which performs the task of optimizing the hyperparameters and selecting the best model, and we also have an outer k-fold cross-validation which is equivalent to the validation-test partition and evaluates the model selected during the inner k-fold cross-validation.
To understand this more clearly, we again take the example used above, where we had a classification problem and needed to find the best model from KNN, Decision Trees and Support Vector Machines along with the best value of hyperparameter. We first start with SVM, but this time we perform nested cross-validation. For the 5-fold cross-validation, we divide our data into 5 equal random parts, where four parts are combined to form the training fold, which creates a training set used to train the SVM algorithm, while the remaining part is used as the test set to evaluate the SVM model. This is done 5 times so that all parts are once considered a testing set. In addition to this, we have an inner 5-fold cross-validation which forms the training fold. Thus at every iteration of the outer fold, the inner fold is divided into 5 equal random parts where 5 iterations take place, and at every iteration, k-1 parts form the training fold while the k part forms the validation fold, and every hyperparameter value goes through the inner k-fold cross-validation. If the model is stable, then at each iteration of the outer loop, the same hyperparameter values get selected. The error values generated by the outer k-fold cross-validation are then averaged to find the generalisation error for the model.
The above steps are then performed for all the other algorithms, and the model which produces the least error is selected.
Repeated K-Fold Cross-Validation
Another variant of k-fold cross-validation is Repeated K-Fold cross-validation, where, for example, if we are performing 5-fold cross-validation, the data is shuffled 5 different times, thus providing us with 25 evaluations. This method is used to make sure that no data point is left behind even after randomly selecting the data points for train and test. Thus here we perform k-fold cross-validation, then reshuffle the data and perform k-fold again, and so on.
Stratified K-Fold Cross-Validation
For example, we have a dataset with 120 observations, and we are to predict three classes - 0, 1 and 2 - using various classification techniques. Now if we perform k-fold cross-validation, then in the first fold, it picks the first 30 records for the test set and the remaining records for the training set. In the next iteration, it picks the second 30 records for the test set, and so on.

This methodology can cause a potential problem where a certain class does not show up in the training set, which will cause the trained model to fail when that class appears in the testing set. This problem can become more severe, especially if the data is sorted by class. On top of all this, it is possible that the dataset has imbalanced classes. For example, out of the 120 records, 60 may belong to class 0, 40 records may belong to class 1, while only 20 may belong to class 2. Thus we need a proper representation of these classes in our training and test dataset, for which we use Stratified k-Fold Cross-Validation. For example, if we perform Stratified k-Fold Cross-Validation with the above-mentioned imbalanced classes, then we first consider all the observations separately as per their class label. Thus we will be dealing with three sets of data: one having observations belonging to class 0, another having observations of class 1, and a third set having observations of class label 2. Each of these sets is then divided into 5 folds, and the first fold of all three classes is joined together to form fold 1. Similarly, the second fold of all three sets of observations is joined together to form the second fold, and so on. This way the class labels get balanced across the training and testing set, and we are able to counter ‘unlucky splits’ from happening.

Leave-one-out and Leave-p-out Cross-Validation
In k-fold cross-validation, we discussed various examples where the value of k was 5. This way, at every iteration, we created a model using 80% of the data. Among the most commonly used values of k is 10, where by doing so we are able to provide 90% of the data to the training set. If we further go with this idea of maximising the number of observations for the training set, we get Leave-one-out cross-validation, which is k-fold cross-validation only, but with k being almost equal to the sample size. This way, if we have 100 observations, then 99 observations are used to form the training set while the one left observation is used for evaluation. Thus if we have n number of observations, we will end up having n iterations, wherein each iteration, a single data point is considered for testing. This method is the best way of learning a function and is more stable than k-fold, and saves us from deciding the number of folds, as the value of k in k-fold can alter results, which makes choosing the right value of k very crucial. However, leave-one-out is extremely computationally expensive, and in comparison, k-fold is much quicker.
A variant of Leave-one-out cross-validation is Leave-p-out cross-validation, where rather than using only one observation for testing, we use p observations as the validation set while the remaining observations are used as the training set. This way the computational cost can be cut down. A Leave-p-out cross-validation with p being 1 is Leave-one-out cross-validation only.
Cross-validation is a very important aspect of data modeling and should be used especially when the data at hand is limited. This way we are able to get accurate results even with limited data, and can save our model from overfitting while providing us with a more accurate estimate of the model's prediction performance.