// supervised learning · regression
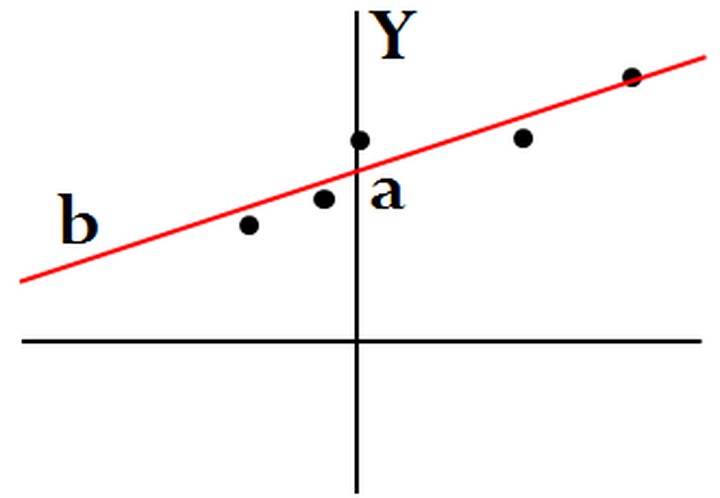
Unlike Classification problems where there are a limited number of labels in the dependent variable, in a Regression Problem the dependent variable contains continuous values, i.e. numbers. Here the aim of predicting is to come up with values that are as close to the original continuous value labels as possible (without causing the model to overfit).

The learning algorithm learns a function by analyzing the observations of the independent variables and their corresponding labels in the dependent variable. It then uses the function to predict the values of the dependent variable for a given set of observations of the independent variable.
A typical example of a Regression Problem can be of 'House Price' where the independent variables are 'Size of House', 'Number of Rooms', 'Neighbourhood' etc, while the dependent variable 'Price of House' is to be predicted.
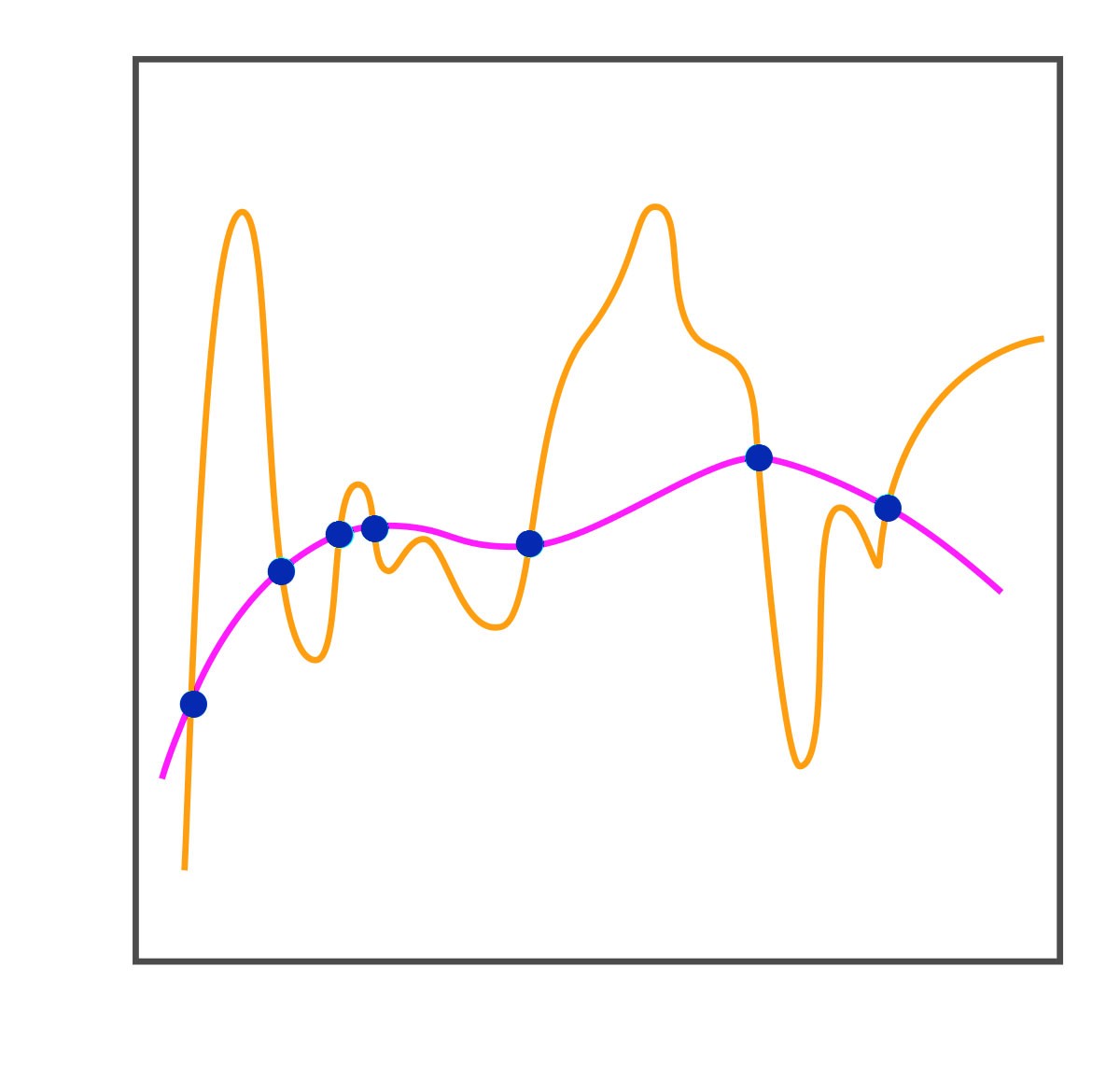
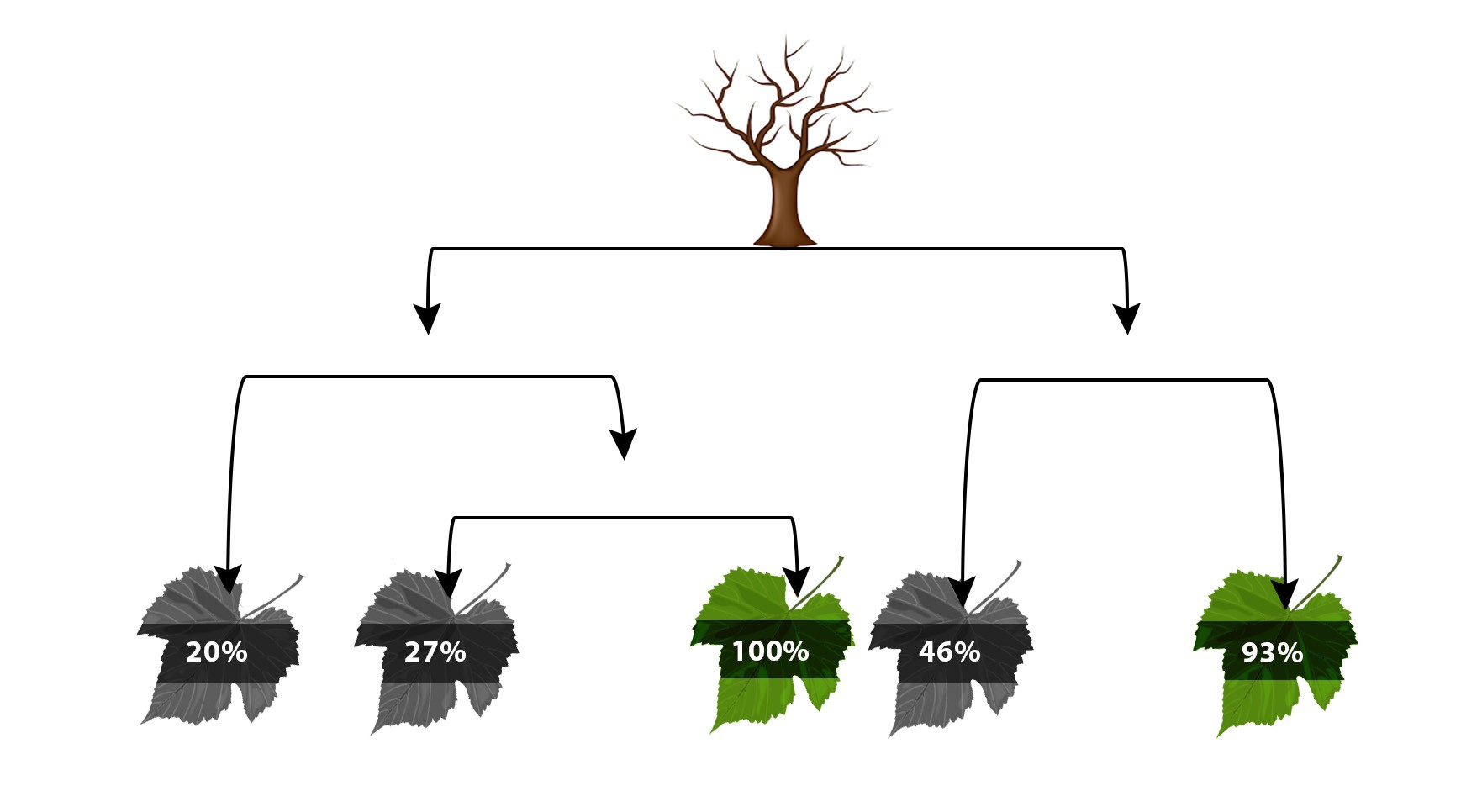
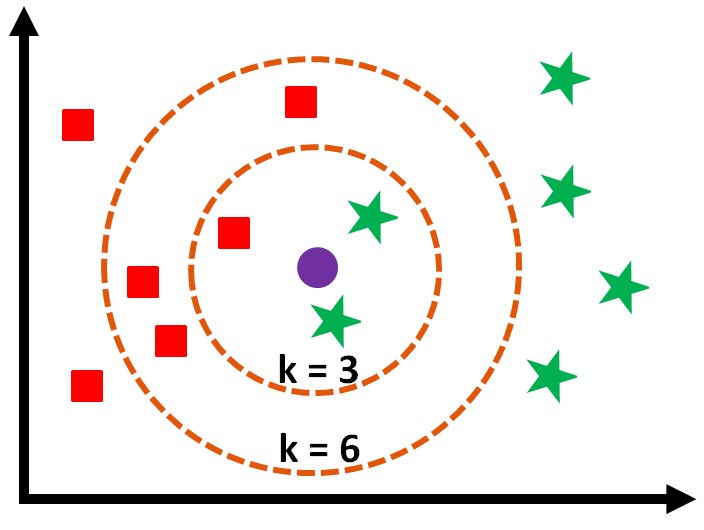
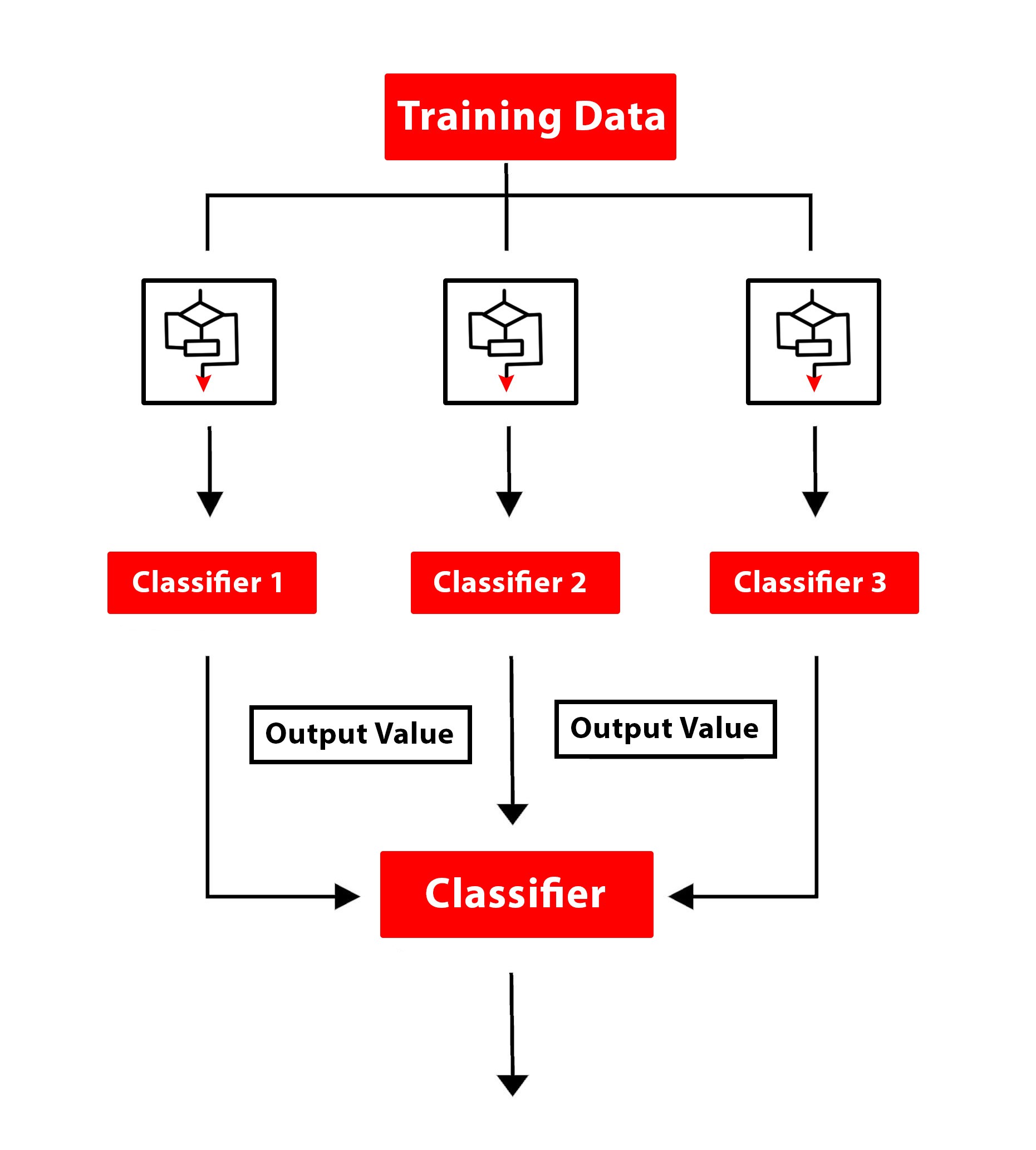
To solve such a problem various learning algorithms can be used which work in a Supervised Learning environment. These include Linear Regression where the relationship between the dependent and independent variable is considered Linear. In addition to this, Regularized Linear Regression can be used to control overfitting. Decision Trees can also be used along with other methods such as KNN, which is an instance based method. Various ensemble methods can also be put to work which use multiple algorithms to come up with an output.
Machine Learning algorithms used only for Regression Problems