Anomaly Detection in Python
Anomaly Detection helps in identifying outliers in a dataset. Various Anomaly Detection techniques have been explored in the theoretical blog Anomaly Detection. In this blog post, we will explore two ways of anomaly detection - One Class SVM and Isolation Forest.
One Class SVM
One Class SVM i.e. One-Class Support Vector Machine is an unsupervised algorithm that learns a decision function to identify outliers. We will be using the Iris dataset which we used for performing clustering.
Adding Libraries
We add some preliminary libraries that will be useful throughout.
import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline
Dataset
Iris dataset is now loaded to detect anomalies in it.
from sklearn import datasets iris = datasets.load_iris() iris_data = pd.DataFrame(iris.data) iris_data.columns = iris.feature_names iris_data['Type']=iris.target iris_data.head()
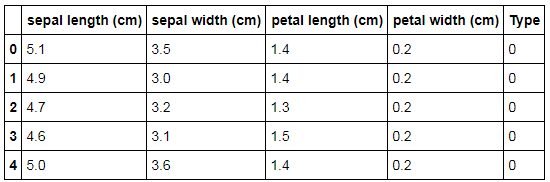
The above output is the complete iris dataset. We will be only requiring the independent variables to identify the outliers.
iris_X = iris_data[['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)']]
Importing OneClassSVM Library
We import OneClassSVM from sklearn.svm which will allow us to create a One-Class Support Vector Machine model.
Building and Fitting Model
In the following code, we first declare the value of nu which defines the upper bound of the fraction of outliers. We then initialize the model and fit it on the iris dataset.
from sklearn.svm import OneClassSVM nu = 0.05 ocsvm = OneClassSVM(kernel='rbf', gamma=0.05, nu=nu) ocsvm.fit(iris_X)

Defining Outliers
We now use the above-created model to identify the outliers in the dataset.
pred_ocsvm = ocsvm.predict(iris_X) pred_ocsvm
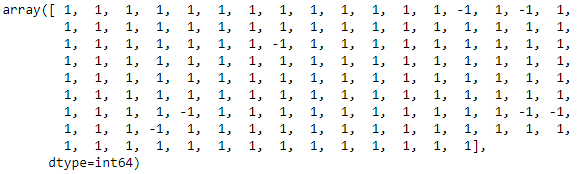
All values that are equal to -1 are outliers.
Outlier Observations
We can create a dataset only having the outlier observations.
X_outliers = iris_X[ocsvm.predict(iris_X) == -1] X_outliers
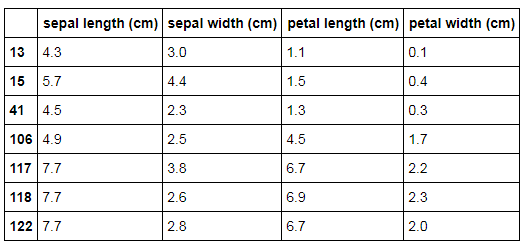
The following observations are considered as outliers by the One-Class SVM.
Isolation Forest
Isolation Forest is an effective and more efficient means of detecting anomalies in a dataset. It isolates observations by randomly selecting a feature and randomly selecting split values between maximum and minimum values of the selected feature. This repeated partitioning can be represented as trees, and hence comes the concept of random decision trees. We will fit the model on the iris dataset and predict the outliers.
Importing IsolationForest Library
We import IsolationForest from sklearn.ensemble which will allow us to create an Isolation Forest model.
Building and Fitting Model
We now build an Isolation Forest model and fit it on the Iris dataset.
from sklearn.ensemble import IsolationForest iforest = IsolationForest(n_estimators=300, contamination=0.10) iforest = iforest.fit(iris_X)
Defining Outliers
We now use the above-created model to identify the outliers in the dataset.
pred_isoF = iforest.predict(iris_X) pred_isoF
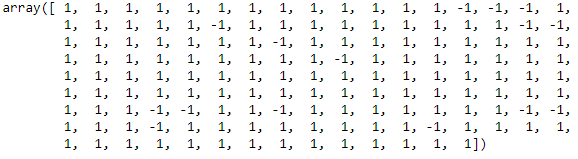
Here values equal to -1 are the outliers.
Outlier Observations
We create a dataset only having the outlier observations.
isoF_outliers = iris_X[iforest.predict(iris_X) == -1] isoF_outliers
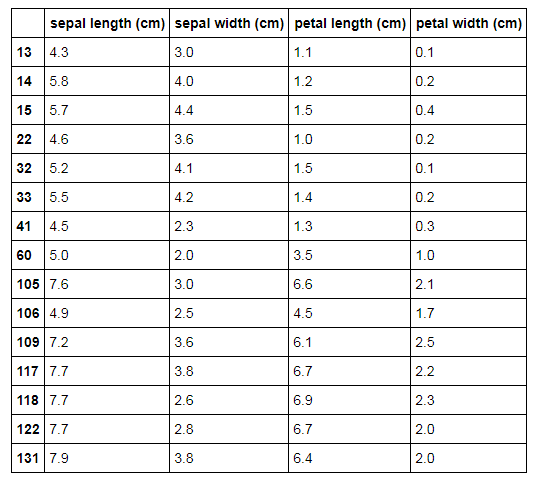
The above observations are termed as outliers by our Isolation Forest model.
In this blog post, we used Python to create models that help us in identifying anomalies in the data in an unsupervised environment. We have created the same models using R and this has been shown on the blog - Anomaly Detection in R.