// application · r
Model Validation in R
Under the theory section, in the Model Validation section, two kinds of validation techniques were discussed: Holdout Cross Validation and K-Fold Cross-Validation.
In this blog, we will be studying the application of the various types of validation techniques using R for the Supervised Learning models. Validation will be demonstrated on the same datasets that were used in the application of various learning algorithms (refer the previous section of application). We will be using a classification learning algorithm for all the cross-validation techniques. Various cross-validation methods will be performed using R to make sure that the model doesn't overfit and will analyze the different accuracy scores generated from various cross-validation techniques.
Dataset
As mentioned above, we will be using the pre-processed Titanic dataset for applying all of the cross-validation techniques that we have used earlier in the application part of the modeling section.
library(gdata)
library(caTools)
library(Metrics)
TitanicD1 = read.xls('C:/Users/user/Desktop/Data Sets/Logistic Regression/TitanicD1.xls')
TitanicD1 = subset(TitanicD1,select = c(1,4,5,6,7,9,10,11,12,13))Validation for Finding Best Model
We will first use the different validation techniques to find the best models. Here we don't perform any hyperparameter tuning and simply see how the model is performing on the test dataset/s and based on the accuracy scores find the best model.
Holdout Cross-Validation
Rather than a simple or degenerate form of cross-validation, Holdout cross-validation is generally known as the 'simple validation' technique. Here we simply divide the dataset into two parts with the first part being the Train dataset where we fit the model and learn the function and the second being Test where the model is made to perform and is evaluated upon. Here we will run a Logistic Regression algorithm on the Titanic dataset and will use the holdout cross-validation technique.
Splitting Dataset
We first split the dataset into train and test. We take a 70:30 ratio keeping 70% of the data for training and 30% for testing.
set.seed(123) split <- sample.split(TitanicD1$Survived,SplitRatio = 0.70) train_set<- subset(TitanicD1,split==T) test_set<- subset(TitanicD1,split==F)
Initializing Logistic Regression Model
Here we initialize the Logistic Regression model.
model_logistic <- glm(Survived~.,data = train_set,family = binomial(logit))
Prediction
The Logistic Regression model now used to predict the Y variable in the Test dataset.
pred_mod_log = predict(model_logistic,newdata =subset(test_set,select = c(2:10)),type="response") pred_mod_log <- ifelse(pred_mod_log > 0.5,1,0)
Calculating Accuracy
We also calculate the accuracy of the model by calculating the R² which tells us of the model's performance on the Test dataset. Note that this procedure will be followed for checking the accuracy of all the upcoming regression model's performance.
Accuracy_log <- accuracy(test_set$Survived,pred_mod_log) Accuracy_log
![Holdout accuracy output: [1] 0.7910448](/assets/mev-r-val-holdout-accuracy.png)
This model provides us with 79% Accuracy however as discussed in the theory section, holdout cross-validation can easily lead our model to overfit and thus more sophisticated methods such as k-fold cross validation must be used.
K-Fold Cross Validation
In this method, we repeatedly divide our dataset into train and test where we fit the model on train and run it on test and get the accuracy score and this way we are able to use all of the dataset and are able to use the same data points for training as well as for testing. In the end, we average all such scores and the final score becomes the accuracy of our model. In R, we can perform K-Fold Cross-Validation using caret package and use the train function to train the model using k-fold cross-validation.
Loading caret package
First, we will load the caret library and then run k-fold cross-validation.
library(caret)
Defining the type of Cross-Validation
We now define the type of cross-validation that will be applied to the model using the trainControl function.
train_control <- trainControl(method="cv", number=5)
Initializing Logistic Regression Model
We then initialize a simple Logistic Regression model using k-fold cross-validation.
model_log <- train(Survived~., data=TitanicD1, trControl=train_control,method="glm",family="binomial")
Cross-Validation Scores
We compute the accuracy scores obtained from each of the 5 iterations performed during the 5-Fold Cross-Validation.
model_log$resample

Final Score
We now use the results attribute to see the details of the final model value.
model_log$results
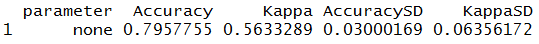
We get 79.5% accuracy when we use K-Fold Cross-Validation. K-Fold Cross-Validation addresses the problem of over-fitting of our model and is providing us with the right picture by giving us the correct, more unbiased and real evaluation score of our model.
Repeated K-Fold Cross-Validation
It is used to run K-Fold multiple times, where it produces a different split in each repetition.
train_control <- trainControl(method="repeatedcv", number=5,repeats = 5) model_log2 <- train(Survived~., data=TitanicD1, trControl=train_control,method="glm",family="binomial") model_log2$resample
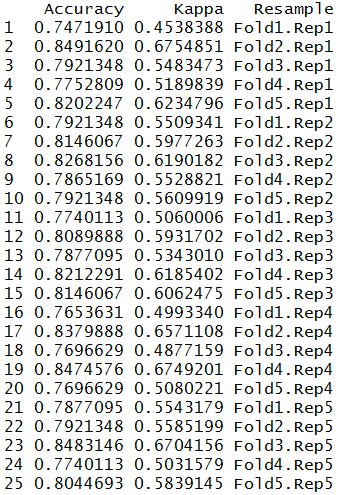
We notice from the output, that 25 iterations resulted in different levels of Accuracy scores. This is because we specified the number of split = 5 and number of times the process to be repeated equal to 5. Therefore, 5X5 equal to 25 iterations.
Bootstrap Cross-Validation
This process takes random samples from the dataset with re-selection and evaluates the model. The codes are as follows. Note that scikit-learn removed its dedicated Bootstrap cross-validation iterator years ago; the resampling technique itself is not deprecated.
train_control <- trainControl(method="boot", number=10) model_log3 <- train(Survived~., data=TitanicD1, trControl=train_control,method="glm",family="binomial") model_log3$resample
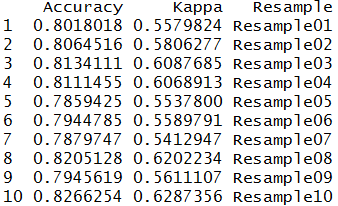
Computing the final result.
model_log3$results

Leave-one-out cross-validation (LOOCV)
This process involves taking (n-1) data samples for training and testing on the single held-out sample.
train_control <- trainControl(method="LOOCV") model_log4 <- train(Survived~., data=TitanicD1, trControl=train_control,method="glm",family="binomial") model_log4$results

Validation for Finding Best Model and Hyperparameters
We used K-Fold Cross Validation not only to find the best model but also to come up with the correct set of hyperparameters. Here we will tune the hyperparameters while we run K-Fold Cross-Validation.
K-Fold Cross-Validation with Grid Search
Here we will perform parameter estimation using grid search with cross-validation. To demonstrate Cross-Validation with Grid Search we will be using Decision Trees as the learning algorithm and we will take the entire pre-processed Titanic dataset for Grid Search with Cross-Validation. Here, the data will be split into train and test using k-fold cross-validation, and hyperparameters will be tuned on the train dataset while the accuracy will be predicted on the test dataset.
Import rpart package
We import rpart package to run the model.
library(rpart)
Listing the parameters for tuning
We then define the hyperparameters.
tune_grid = expand.grid(cp=c(0.1,0.001,0.01,0.02,0.03))
Initializing and Fitting Model
We initialize the Decision Tree model and then fit it on the dataset.
control <- trainControl(method ="cv",number =3,search = "grid") dtc_gridsearch <- train(Survived~.,data = TitanicD1,method="rpart",tuneGrid=tune_grid,trControl=control)
Best Parameter values for the model
We now use bestTune attribute to find the values of parameters selected during the above process.
dtc_gridsearch$bestTune
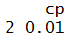
Predicting the values
We predict the values of the dependent variable. This will allow us to compute the accuracy score.
pred_dtc_gs <- predict(dtc_gridsearch,newdata = subset(TitanicD1,select = c(2:10)))
Computing Accuracy Score
We now compute the R-Square which helps us in evaluating the model.
library(Metrics) Accuracy_DTC <- accuracy(TitanicD1$Survived,pred_dtc_gs) Accuracy_DTC
![Grid Search accuracy output: [1] 0.8417508](/assets/mev-r-val-gs-accuracy.png)
We get 84% accuracy from the Decision Tree model. Note that this process resulted in very high accuracy. This may be due to the entire dataset getting leaked during the modeling process resulting in overfitting. Therefore, to avoid this problem we can use two methods: A combination of Holdout and K-Fold-Cross Validation or can perform Nested Cross-Validation.
K-Fold and Holdout Cross-Validation
A most common way of avoiding the model from getting overfit is by using a combination of K-Fold and Holdout Cross-Validation. So far we have used the entire dataset when using K-Fold Cross-Validation and this is indeed the biggest advantage of K-Fold that it allows the use the of entire dataset for learning the function and testing it. However, this can potentially lead to overfitting and to avoid it we compromise with this advantage of k-fold which allows us to use the whole of the dataset. Here we first use Holdout method to split the dataset into Train and Test. This Test dataset acts as an unseen data and is used to evaluate the model. We then use the Train dataset for K-fold Cross-Validation where this Train dataset is repeatedly split into Train and Test and the model gets trained and tested on all of this Train dataset. The model we acquire from this method is then used to predict the values of the unseen dataset i.e. the Test dataset obtained from the Holdout method and the accuracy score got from this model helps in giving us a better, unbiased picture of the performance of our model. This method can be used in any type of K-Fold Cross-Validation for either selecting the best model or for finding the best parameters or both.
Here we will perform the K-Fold Cross-Validation with Grid Search using the Random Forest as the learning algorithm as done above however this time we will fit the model on the Train dataset obtained from the Holdout Cross-Validation and evaluate its performance on the Test dataset (also got from Holdout Cross-Validation).
Splitting Data using Holdout Cross-Validation
We start from the scratch and first take the preprocessed Titanic dataset and create two datasets with the X dataset having all the independent feature and Y dataset having the dependent variable. We then divide the dataset into Train and Test using Holdout method. Here the Test dataset will act as unseen data and it is 30% of the whole dataset.
TitanicD1 = read.xls('C:/Users/user/Desktop/Data Sets/Logistic Regression/TitanicD1.xls')
TitanicD1 = subset(TitanicD1,select = c(1,4,5,6,7,9,10,11,12,13))
set.seed(123)
split <- sample.split(TitanicD1$Survived,SplitRatio = 0.70)
train_set<- subset(TitanicD1,split==T)
test_set<- subset(TitanicD1,split==F)Declaring Parameters
We now declare the hyperparameters that we need to tune.
tune_grid = expand.grid(cp=c(0.1,0.001,0.01,0.02,0.03))
Initializing and Fitting Model
In this step, we initialize and build the Decision Tree model using rpart model and fit it on the Train dataset rather than the whole dataset as done earlier.
control = trainControl(method ="cv",number =3,search = "grid") dtc_gridsearch <- train(Survived~.,data = train_set,method="rpart",tuneGrid=tune_grid,trControl=control)
Best Parameters
bestTune attribute can be used to find the best parameters.
dtc_gridsearch$bestTune
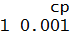
Predict and Check Accuracy
The above model with the above-mentioned values of hyperparameters is used to predict the values of the dependent variable in the Test dataset and also the accuracy is calculated.
pred_dtc_gs <- predict(dtc_gridsearch,newdata = subset(test_set,select = c(2:10))) Accuracy_DTC_GS <- accuracy(test_set$Survived,pred_dtc_gs) Accuracy_DTC_GS
![K-Fold+Holdout accuracy: [1] 0.7910448](/assets/mev-r-val-kfold-holdout-accuracy.png)
The accuracy comes out to be 79% which is less than we received earlier when we used the whole dataset however this might be because we are able to address the problem of overfitting now.
In this blog post, we found how the accuracy score can change upon changing the cross-validation technique. This indicates that the problem of overfitting is ubiquitous and can be highly detrimental if it is not properly addressed. To save our model from overfitting and for getting an unbiased picture of our model's performance various cross-validation techniques can be used. While the various k-fold cross-validation methods are good at addressing the problem of overfitting, they are computationally expensive and can cause problems especially when the dataset is large enough. On the other hand, holdout method is simple and is useful especially when dealing with large datasets but can lead the model to overfit. Thus it becomes important to choose the right model validation technique. All such cross-validation methods are also explored in Python in Model Validation in Python.