// supervised learning · regression & classification
Ensemble means a group of items. Ensemble methods mean using groups of models which are integrated in such a way that they are able to address the bias-variance problem, which often occurs when finding a solution by creating only a single model. Ensemble methods are meta-algorithms that make use of other modeling algorithms as components to learn a collection of predictors.

These Ensemble methods can be used for problems solved using Supervised Learning and Unsupervised Learning, however here only the use of ensemble methods for Regression and Classification problems, solved in a supervised learning setup, is discussed.
Ensemble models can be of two types: Homogeneous and Heterogeneous. Under a Homogeneous ensemble model, only one induction algorithm is used, employing a single learning algorithm (such as Logistic Regression) along with Cross Validation (generally k-fold) to form several base models. Heterogeneous Ensemble Models, by contrast, use different induction algorithms, employing multiple learning algorithms (such as Logistic Regression, KNN, SVM etc.) to build different base models. In both cases, the resulting set of predictors/classifiers is combined through algebraic or voting methods to predict or classify new data points.
The idea behind ensemble models is to use several weak models to come up with a relatively strong model, much like asking several people a question and combining their answers rather than relying on one. There are mainly three types of Ensemble Methods explored below: Bagging, Boosting, and Stacking.
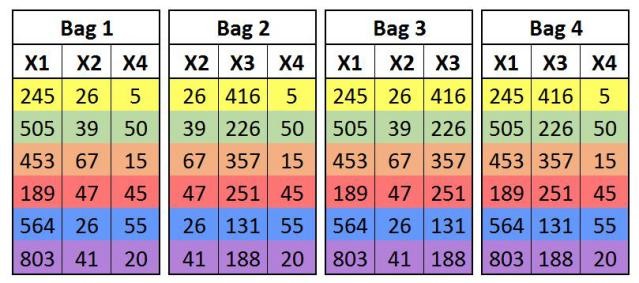
Bagging is a type of ensemble method where sampling of the data is done in such a way that the problem of overfitting can be addressed. There are various types of Bagging such as Pasting, Bootstrapping, Random Subspaces and Random Patches. It is the Bootstrapping method, where several subsets of data from the training set are chosen randomly with replacement, that is often considered the Bagging method. The most common algorithm used during the bagging process is decision trees, and a popular variant of Bagging is Random Forest.
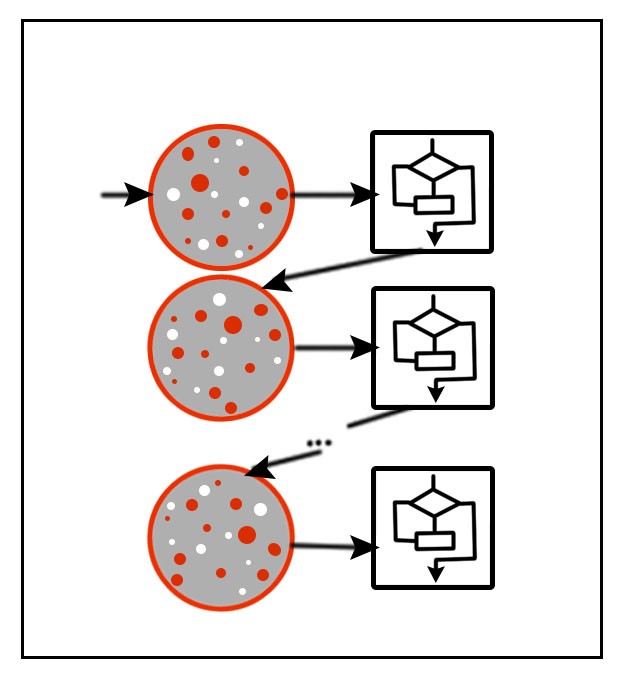
Boosting is another ensemble method where the output of the previous model affects the next model, learning the function sequentially. There are multiple types of Boosting such as Adaptive Boosting, Gradient Boosting and Extreme Gradient Boosting. Adaptive Boosting uses a number of weak learners where the function is learnt sequentially by assigning weights to the errors. Gradient Boosting extends Adaptive Boosting by using Gradient Descent, and Extreme Gradient Boosting is a more sophisticated variant of Gradient Boosting.
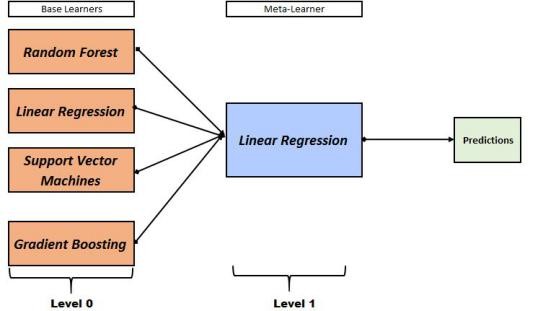
When a lot of different models are applied to data simultaneously, this method of meta-ensemble modeling is known as Stacking. Here there is no single function; rather there is a meta-level where a function is used to combine the outputs of different functions, so information from various models is combined into a unique model. This is among the most advanced forms of data modeling, commonly used in data hackathons and other online competitions where maximum accuracy is required. Stacking models can have multiple levels and can be made very complex using various combinations of features and algorithms.