// shared: regression & classification
Stacking
Stacking, also known as Super Learning, is an ensemble method. It can make use of various Regression and Modeling algorithms, Bagging and Boosting, Cross-Validation and Bootstrapping (for training the algorithm on different training datasets to control overfitting), Feature Selection Techniques, Regularization Techniques, and various hyperparameter settings to come up with a single model, and can be said to be the pinnacle of all that has been discussed on this site.
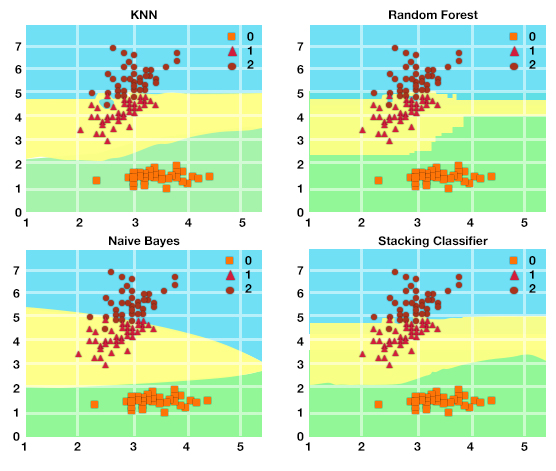 KNN, Random Forest, Naive Bayes, and a Stacking Classifier compared side by side, illustrating how stacking combines multiple predictive modeling algorithms">
KNN, Random Forest, Naive Bayes, and a Stacking Classifier compared side by side, illustrating how stacking combines multiple predictive modeling algorithms">
Level-1 Stacking
There are many forms of Stacking, such as blending, and in simple words, it is simply a process where we train several base learners on the training dataset. These base learners, unlike Bagging and Boosting, can be different (Bagging and Boosting can also use different modelling algorithms simultaneously; however, this is generally not done). The output of these base algorithms is handled by one algorithm that is used to combine the output of these base learners, or we can say that the meta-learner is trained on the predictions of these base learners, and by learning when the base learners were right or wrong, the meta-learner comes up with its own final predictions. There are two types of meta-learners: meta-classifiers and meta-regressors. Generally, logistic regression is used as the meta-classifier and linear regression is used as the meta-regressor.
To further elaborate, let’s take an example of 1-level stacking where we have to solve a regression problem. We have a dataset of 1000 records, and we divide the dataset into train and test, with 60% for train and 40% for test. At Level-0 (known as the Model Library) we build four models: Random Forest, Linear Regression, Support Vector Machines, and Gradient Boosting (with one-level decision trees for creating base models). We come up with predictions, and they all have some error. At Level-1 we introduce a meta-learner (let’s say we took Linear Regression as the meta-learner) to optimally combine the base-model predictions to form new predictions, which it does by estimating weights for each base model by minimizing the least-squared error. Thus the role of the meta-learner is to find how to best combine the output of the base learners. This model created by the meta-learner can now be used on the test dataset to come up with final predictions, and its accuracy can be checked.
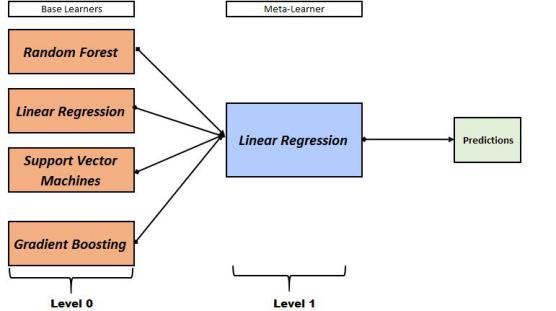
Methods for creating complex Stacking Models
However, this is a very simple method of stacking and can be made very complex. Let’s understand how the process of stacking can be made complex.

Adding Levels
Let’s say we create a two-level stacked ensemble model for a classification problem. Here we create a model library by using 8 modeling algorithms: Artificial Neural Networks (ANN), K’s Nearest Neighbour (KNN), Logistic Regression, Decision Tree, Bagging with Decision Trees, Random Forests, Naive Bayes, and Gradient Boosted Trees. Now we enter Stage 1, where the predictions from these 8 models are used to train 2 new models. We choose these two models to be Logistic Regression and Gradient Boosted Trees. In Stage 2 of ensemble stacking, the predictions provided by the two models from Stage 1 are used as inputs to train a single new model, let’s say a logistic regression model, and this creates the final ensemble model.
Adding Hyper-parameters
There are many hyperparameters that can be tweaked in various models, such as the depth of the tree in decision trees, the number of K in K’s Nearest Neighbour, the number of bags to be created in bagging, the number of trees to be created in random forests, the number of base models to be created in boosting, etc. And this is not even the tip of the iceberg. Each of these algorithms has at least 6-12 hyperparameters that can be tweaked. Let’s say we tweak the models to differentiate them from one another, and using the same 8 models, we are able to come up with 32 different single models to create the model library at Level-0. We can then create 8 models by tuning the parameters at Level 1, and can use two different models at Level 2, and add a new level to create the final output.
Feature Selection
Each of these models will use features, and these models can further be made distinct by using different feature extraction/selection techniques. Thus, with a combination of feature sets and hyperparameters, we are able to double the 32 models and use 64 models to create the model library, and then use 15 models for the Stage 1 ensemble and 2 models for the Stage 2 ensemble, and a model as the final meta-learner at Stage 3, to come up with predictions.
Training models at different training datasets
To make things more complicated and error-proof, we have to make the models less vulnerable to overfitting, and for this, we can apply cross-validation in training each of these models. Let’s say we use k-fold cross-validation at Level 0, where k=10; then we will have predictions from each fold of these cross-validated algorithms. Thus, if we have 64 algorithms, 10 folds, and 10,000 data points to be predicted, then for Level 0 we will have 10 × 10,000 × 64 predictions. Here, like out-of-bag error, we use out-of-fold predictions, and the sum of squared errors between the out-of-fold predictions and actual values provides us with the cross-validation error of the model; this method is used at different levels of stacking. We can also perform bootstrap sampling, where we use out-of-bag predictions to compute the error between predicted and actual values. These steps are very important, as they decrease the chance of overfitting the ensemble model. This method helps to avoid leakages. For example, if we use all of the training dataset to train 4 models (e.g. Random Forest, Linear Regression, Support Vector Machines, and Gradient Boosting) and provide the four predictions of these four models to the meta-learner (e.g. Linear Regression), then the ensemble model created by the meta-learner can overfit, as the target variables will be used twice.
Regularization
Along with using cross-validation, we can train the models by applying various regularization, such as L1 and L2. These also help in controlling the model from becoming a victim of overfitting.
Weights
Different weights can be provided to different base models. We can assign equal weights to them; however, one model may be essentially better than the other. The weights of the models can be found using neural networks, forward selection learners, and selection with replacement.
We can make the stacking models as complex as we want and can come up with our own stacked ensemble that provides us with the best result. Such stacked methods are commonly used in data science competitions and are used for very accurate predictions. (The first place for the Otto Group Product Classification challenge was won by a stacking ensemble of over 30 models whose output was used as features for three meta-classifiers: XGBoost, Neural Network, and AdaBoost (engineered features and cross-validation were also used). Similarly, the model that won the 2015 KDD Cup used a 3-stage stacked ensemble model by creating 64 single models to build the model library, using variations of Neural Networks, Factorization Machines, K’s Nearest Neighbour, Logistic Regression, Random Forest, and Gradient Boosting, along with other machine learning algorithms; different sets of features were also used to diversify the models.) Thus Stacking can be used to have very precise predictions by using various models that can be diversified by using different architectures, hyperparameter settings, and training techniques.