// feature engineering
Feature Scaling
Feature Scaling is among the most important steps of feature engineering and data pre-processing as a whole. To understand feature scaling intuitively, we can take an example of a dataset where we have two variables, Income and Average Duration of Call. To compare them, we require them to be on the same scale, as Income, for instance, is in dollars and call duration is in minutes. To compare such variables, they are required to be on the same scale, and this is where feature scaling helps. Thus, when certain attributes have a higher ‘magnitude’ than others due to values being in different units of measurement, it becomes necessary to scale all such attributes to bring them to comparable/equivalent ranges.
Where to Use Feature Scaling
Before understanding the various methods through which features can be scaled, it is important to understand the importance of feature scaling and the implications if features are not scaled. Many machine learning algorithms require feature scaling, as this prevents the model from giving greater weightage to certain attributes as compared to others, such as:
Distance-based models, for example, require features to be scaled, as algorithms such as K-Means use Euclidean distance to calculate the distance between two points, and if one feature is in a different unit of measurement causing it to have a broad range of values, it can influence the calculation, causing biased and wrong results. Thus the change in the metric space, i.e. the Euclidean distance between two samples, will be different after transformation.
Gradient Descent, an optimization algorithm often used in Logistic Regression, SVM, Neural Networks etc., is another prominent example where, if features are on a different scale, certain weights are updated faster than others. However, feature scaling helps in causing Gradient Descent to converge much faster, as standardizing all the variables onto the same scale, for example for a linear regression, makes it easy to calculate the slope (y = mx + c), where we normalize the m parameter to converge faster.
Feature Extraction techniques such as Principal Component Analysis (PCA), Kernel Principal Component Analysis (Kernel PCA), and Linear Discriminant Analysis (LDA), where we have to find directions by maximizing the variance, also benefit from scaling the features, as we can avoid a potential error of emphasizing variables that have large scales of measurement. For example, if we have one component (e.g. work duration per day) where variation is less than another (e.g. monthly income) because of their respective scales (hours vs. dollars), PCA might determine that the direction of maximal variance corresponds more closely with the ‘income’ axis. If the features are not scaled, a change in the duration of one hour can be considered much more important than the change in income of one dollar. Generally, the only family of algorithms that can be called scale-invariant are tree-based methods; otherwise all the other algorithms, such as Neural Networks, tend to converge faster, K-Means generally gives better clustering results, and various Feature Extraction processes provide better outcomes with pre-processed scaled features.
Methods of Feature Scaling
There are multiple ways through which features can be scaled, with each method having its own utility and strength. The various methods of scaling are listed below.
Min-Max Scaling (aka Rescaling or Normalization)
This is one of the simplest ways of scaling, where the values are scaled in the range between 0 and 1, or from -1 to 1. The formula for scaling the values to range between 0 and 1 is:
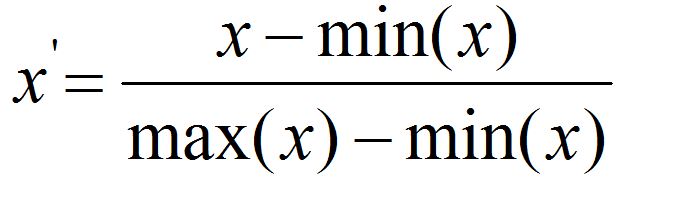
The formula for scaling the values to range between -1 and 1 (making 0 the centre) is:
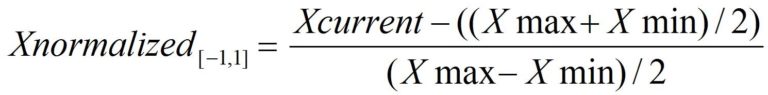
It is a popular alternative to standardization (mentioned below). Note, however, that Min-Max scaling is quite sensitive to outliers, as a single extreme value sets the minimum or maximum and squeezes the remaining values into a narrow band; standardization or robust scaling handles outliers better.
This method is used when algorithms such as K-Nearest Neighbour, where distances are to be calculated, or regression, where coefficients are to be prepared, are involved. In models where the functioning of the model relies on the magnitude of values, normalization is often done. However, for all the above-mentioned scenarios, standardization (mentioned below) is more commonly used. There are certain applications where Min-Max scaling is more useful than standardization, such as in models where image processing is required. For example, in various classification models where images are classified based on pixel intensities which range between 0 to 255 (for the RGB colour range, i.e. for coloured images), the rescaling process requires the values to be normalized within this range only. Various Neural Network algorithms also require the values of features to range between 0 and 1, and Min-Max scaling comes in handy here.
Z Score Normalization aka Standardization
Z-score normalization simply means rescaling the features so that the feature has a mean of zero and a standard deviation of one. This concept has been explained under Inferential Statistics, thus the feature(s) will have the properties of a standard normal distribution.
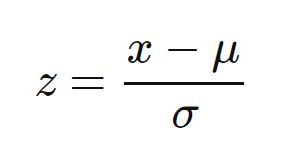
Standardization is one of the most important and widely used rescaling techniques, and is used in models that use machine learning algorithms such as Support Vector Machines, Logistic Regression, and Neural Networks etc. K-Means algorithms and other clustering algorithms also benefit from standardization, especially where Euclidean distance is to be calculated. Models that rely on the distribution of features, such as Gaussian processes, also require standardization of features. Various feature extraction techniques also require the features to be scaled, and standardization is the most commonly used method, as Min-Max scaling provides smaller standard deviations, whereas when using feature extraction techniques such as Principal Component Analysis, we are concerned with the components that maximize the variance.
Feature Scaling is one of the most important parts of data pre-processing, and if required, must be undertaken before applying any kind of machine learning algorithm. There are mainly two methods, Normalization and Standardization, for scaling features, each having its own advantages and disadvantages, and should be used depending upon the algorithm being used in the model.