// feature selection
Wrapper Methods
Wrapper Methods are an automatic feature reduction process which involves no human intervention, where we build a model, and based on its output, another model is created by selecting features until the subset of features is found that gives the maximum accuracy. Thus it picks features at each step of the model building process, thereby selecting features until it reaches the highest accuracy. Various predictive models are used to score feature subsets based on their coefficients, error rate of the model, and other statistical metrics such as t-stats, R-square, AIC, etc.
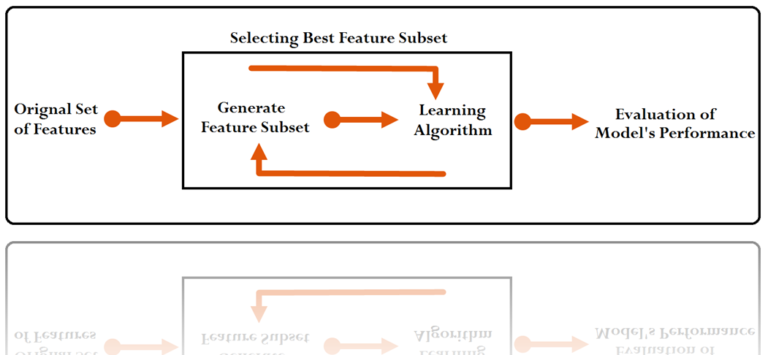
Types of Wrapper Methods
There are two types of Wrapper Methods: Stepwise Regression and Recursive Feature Elimination.
Stepwise Regression
Under the Stepwise method, all the provided independent variables are considered, and a regression model is built by adding or dropping features one at a time based on different criteria. The stepwise methods can be divided into Forward Selection, Backward Elimination, and Standard Stepwise Regression.
Enter Method
Before explaining the various types of Stepwise Regression methods available, it is important to first understand another method, the ‘Enter Method,’ which will help us understand how stepwise regression works.
For example, we have a dataset with 40 features, and there is a regression problem, and we decide to run a linear regression and select features through the Enter Method. In this scenario, we select all 40 features and run a linear regression and get an output where the regression coefficient, p-value, and VIF for all features are provided. We then begin eliminating features one by one, or even multiple features at a time, and then re-run the model to see if the model’s accuracy has dropped significantly or not. We drop those features where the p-value is high, indicating that they share a weak relationship with the dependent variable.
To resolve the problem of multicollinearity, we also consider VIF, which is the Variance Inflation Factor that basically indicates the relationship a feature has with other variables. Ideally, variables with VIF = 1 should be considered so that all our variables are independent, minimizing the chances of multicollinearity; however, this is not possible, because if variable Y is related to A and to B, then there will be some relation between A and B too. Therefore the threshold becomes 2 (for Risk Modelling, Risk Analysis and Clinical Trials) or 3-4 (for Marketing and Sales Analysis).
Thus we also remove variables that have high VIF and p-value, so, for example, if we have a variable with high VIF and p-value, we can create a correlation matrix and look at the variables that are correlated with this variable, and from this group of correlated variables, we can select the optimal number of variables after checking their respective p-value and VIF as well. The domain knowledge is also important here, as certain variables that may be very important in real life may have a high p-value and VIF but may be required to be kept in the model.
Through this process, the model’s accuracy is constantly checked, and if a feature significantly reduces the accuracy, then that feature is kept, overriding our set parameters of p-value and VIF. Thus, after running multiple iterations, we require a model that has high accuracy (in the case of a linear regression model, a high R-square, with its difference from the adjusted R-square being within permissible limits, which is 1 to 2%), has all the important variables (all features have a p-value of 0.05 or below), and has minimal multicollinearity (VIF in the acceptable range of 1 to 4).
The Enter Method is feasible if the dataset is small, having a limited number of features; however, if the dataset is huge, then it becomes a very tedious task, requiring a more automated process, and that is where Stepwise Regression helps us.
Forward Selection
Forward Selection is a rarely used method where we add features at each step of the modeling process. We start with no features in the model and then add one feature at a time, checking if it is significant; if found insignificant, the variable is dropped, otherwise it is kept, and the second feature is added with its significance checked in the same manner, and so forth, until all the features in the model reach a significance level of, for example, 95%. In terms of model accuracy, it keeps adding features as long as they add to the accuracy of the model, and stops when an additional feature does not contribute towards the model’s accuracy. This process has a drawback in that it does not consider multicollinearity, and collinear features can be significant with the dependent variable and can add to the accuracy of the training model but eventually cause a problem of overfitting, where the model fails on the testing data. Compared to the Enter Method, VIF is not considered here, and the selection is done on the basis of p-value and R-square only. Also, if a feature is entered initially but, when combined with other variables, causes a drop in the accuracy of the model or itself becomes insignificant, such a feature cannot be dropped.
Backward Elimination
In Backward Elimination, all the features are added, and in each iteration, the least significant feature is dropped. This process is repeated until all the insignificant features are removed. The level of significance can be set, and if the significance level is set at 95%, then the final output will have only those features whose p-value is less than 0.05. In terms of model accuracy, each insignificant variable may drop or increase the model’s accuracy, and the iterations are stopped when no major improvement can be found in the model’s accuracy from dropping the variables. The major drawback of the Backward Elimination method is exposed when a variable is dropped initially but becomes significant later (due to combinations of features) and may have contributed towards the model’s accuracy, but under such a scenario the feature is dropped permanently. Also, VIF is not considered, so it doesn’t deal with the problem of multicollinearity.
Standard Stepwise Regression
This is the most widely used Wrapper method for selecting features, where at each step, features are added and removed on the basis of improvement in R-square, thus acting as a combination of Forward Selection and Backward Elimination. As variables are constantly added and dropped considering the model’s accuracy, the problem of multicollinearity is also resolved to a certain extent. Most of the time, the Enter Method and Standard Stepwise Regression produce identical results, but they can differ when the dataset is very small, as in such circumstances a loss of variable is likely to happen if standard regression is used; however, if the datasets are large enough, both produce similar outputs.
Thus, by using Stepwise Regression, we can maximize the prediction power of a model with a minimum number of predictor variables, making the model resistant to overfitting.
Recursive Feature Elimination
Under the Recursive Feature Elimination method, models are repeatedly constructed. These models can be regression models or any other machine learning model, such as Support Vector Machine, K-Nearest Neighbours, etc. Each time a model is built, the best or worst performing features are chosen and set aside. The basis of this performance is generally the feature’s coefficient. The process is then repeated with the remaining features and is stopped when there are no more features left to create a model with. All these features are then finally ranked on the basis of the order of their elimination, providing us with a subset of the best performing features.
One must note that this method uses a greedy optimization algorithm for finding the best features, as it makes the choice of selecting features at each iteration on the basis of what seems best at that particular ‘moment’ or stage of the process, hoping to eventually find the subset of the best performing features.
Also, it must be remembered that this is a fairly unstable method, as it is built on other models and heavily relies on the type of model being used to rank the features. To counter this, Recursive Feature Elimination should be built on top of other modeling/selection algorithms that can also perform regularization, such as Ridge Regression. Thus these models must be used to build the model, making the process of Recursive Feature Elimination more stable and providing more stable and better results.
Other Methods
Stability Selection
Here a selection algorithm is chosen in the way we chose in Recursive Feature Elimination; however, this time the algorithm is applied not on all the data but rather on different subsets of data, also with a different subset of features. This process is repeated a couple of times, and results for each feature are provided, with this result being generally based on how many times a feature got selected across the various iterations (if the feature was selected for the iteration). This information is collected and aggregated to give us an idea of the most important features. A question can arise here as to whether something along these lines can be done by other methods. If we compare it with one of the most popular methods for feature reduction, Principal Component Analysis, then PCA is unable to provide us with consistent estimates of the true direction of maximal variability if there are a lot of features and not much data in a dataset, and here a method such as Stability Selection can be used, as it combines a feature selection algorithm with sub-sampling strategies, providing us with a set of stable variables.
There are multiple wrapper methods one can choose from, but the easiest and most popular methods are Standard Stepwise Regression and Recursive Feature Elimination, as they are good automated methods that can consider the various aspects we might consider when selecting features (as shown in the Enter Method). Wrapper Methods are much more efficient and quicker than Filter Methods. There is another type of feature reduction method known as Embedded Methods, which is explored in the next blog.